
브래의 슬기로운 코딩 생활
운영체제 중간고사 정리 본문
운영체제(OS: Operating System)
데이터 처리 장치(컴퓨터, 노트북 또는 스마트폰 등)의 전원을 켜면 가장 먼저 만나게 되는 소프트웨어
임베디드(Embedded) 운영체제
- CPU의 성능이 낮고 메모리 크기도 작은 시스템에 내장하도록 만든 운영체제
- 임베디드 운영체제가 있는 기계는 기능을 계속 향상할 수 있음 = 소프트웨어 업데이트
펌웨어(Firmware)
- 프로그램이라는 관점에서는 소프트웨어와 동일하지만 하드웨어와 밀접한 관계를 가지고 있다는 점에서 일반 응용소프트웨어와 구분되어 펌웨어는 소프트웨어와 하드웨어의 특성을 모두 가지고 있다고 할 수 있다.
운영체제의 정의
-사용자와 하드웨어 사이의 중간 매개체로 응용프로그램의 실행을 제어하고, 자원을 할당 및 관리하며, 입출력 제어 및 데이터 관리 등의 서비스를 제공하는 소프트웨어
시스템 소프트웨어
시스템 인터페이스
-응용 프로그램이나 사용자에게 컴퓨터 자원을 사용할 수 있는 인터페이스를 제공
컴퓨터 자원 관리
- 응용 프로그램이나 사용자에게 모든 컴퓨터 자원을 숨기고 정해진 방법으로 컴퓨터 자원을 사용할 수 있도록 제한
부팅(Booting)
- 운영체제가 각종 서비스지원을 하기 위한 일련의 준비 과정
- 컴퓨팅 시스템을 시동하거나 초기화
- 응용프로그램의 구동을 위한 운영체제의 동작 환경을 구성
- 사용자 명령을 받아들이기 위한 상태 진입(준비상태)
콜드부팅: 컴퓨터의 리셋버튼이나 전원버튼을 눌러서 재부팅하는 것
웜부팅: 윈도우에 다시시작 버튼으로 재부팅하는 것
운영체제의 역할
자원 관리
자원 보호
하드웨어 인터페이스 제공
사용자 인터페이스 제공
운영체제의 역할과 목표
효율성
안정성
확장성
편리성
운영체제 개요 - 운영체제 역사
1940년대
에니악(ENIAC)
- 최초의 컴퓨터
운영체제가 없음 = 0기
진공관(vacuum tube, electron tube)이라는 소자(18,000여개)를 사용
전선을 연결하여 논리회로를 구성하는 ‘하드와이어링’ 방식으로 동작
1950년대
천공카드 시스템
천공카드(Punched Card) 리더를 입력장치로, 라인 프린터를 출력장치로 사용
일괄 작업 시스템
천공카드리더기(입력)와 라인프린터(출력)를 사용
모든 작업을 한꺼번에 처리
• 프로그램 실행 중 사용자가 데이터를 입력하거나 수정하는 것은 불가능
운영체제 개념 도입
• 메인메모리에는 운영체제 상주 영역과 사용자 영역으로 구분
1960년대
대화형 시스템(Interactive system)
- 모니터와 키보드 이용
시분할 시스템
- 하나의 CPU로 여러 작업을 동시에 실행하는 기술
- 한 번에 하나의 작업만 가능한 일괄 작업 시스템에 비해 효율성이 뛰어남
- 시간을 분할하는 방법 때문에 여러 작업이 동시에 실행되는 것처럼 보임
다중 프로그래밍
다중 프로그래밍 시스템에서는 CPU 사용 시간을 아주 잘게 쪼개어 여러 작업에 나누어 줌
1970년대
분산 시스템
- 개인용 컴퓨터와 인터넷이 보급
- 값이 싸고 크기가 작은 컴퓨터들을 하나로 묶어서 대형 컴퓨터의 작업을 수행
- 여러 컴퓨터로 작업을 처리하고 그 결과를 상호 교환
1990년 이후
클라이언트/서버 시스템
- 작업을 요청하는 클라이언트와 요청 작업을 처리하는 서버의 이중구조로 나뉨
- 웹 시스템이 보급된 이후 일반인들에게 알려짐
2000년 이후
P2P 시스템
- 클라이언트/서버 구조의 단점인 서버 과부하를 해결하기 위해 만든 시스템
- 서버를 거치지 않고 사용자와 사용자를 직접 연결
- 냅스터(mp3공유 시스템)에서 시작하여 현재는 메신저나 토렌트 시스템에서 사용
그리드 컴퓨팅
필요한 기간만큼만 컴퓨터를 사용하고 사용한 기간만큼만 돈을 지불하는 컴퓨팅 환경
• SaaS(Software as a Service: 서비스형 소프트웨어)는 사용한 소프트웨어 비용을 지불
클라우드 컴퓨팅
언제 어디서나 응용 프로그램과 데이터를 자유롭게 사용할 수 있는 컴퓨팅 환경: 그리드 컴퓨팅 + SaaS
하드웨어를 포함한 시스템이 구름에 가려진 것처럼 사용자에게 보이지 않는 환경이라는 의미
사물 인터넷(IoT: Internet of Thing)
사물에 센서와 통신 기능을 내장하여 인터넷에 연결하는 기술
운영체제 개요 - 운영체제 구조와 종류
커널과 인터페이스
커널(Kernel)
- 운영체제의 핵심(Core)
- 프로세스 관리, 메모리 관리, 저장장치 관리와 같은 운영체제의 필수 기능을 모아놓은 것
인터페이스(IF: Interface)
- 커널에 사용자의 명령을 전달하고 실행 결과를 사용자에게 알려주는 역할
- GUI(Graphical User Interface) : 그래픽을 기반한 사용자 인터페이스
- CLI(Command Line Interface) : 텍스트기반의 사용자 인터페이스 (TUI와 다름)
시스템 호출
시스템 호출
- 컴퓨터의 자원을 이용하기 위해 사용자 인터페이스 또는 응용프로그램이 커널에게 접근하기 위한 수단
- 커널(Kernel)이 제공하는 시스템 자원의 사용과 연관된 함수
- 커널이 제공하는 인터페이스
- 응용프로그램이 커널 영역에 진입할 수 있는 유일한 수단
실행 중인 프로그램과 운영체제 간의 인터페이스
• 하드웨어 자원 접근 또는 운영체제가 서비스를 이용 할 때는 시스템 호출을 사용해야 함
운영체제는 커널 서비스를 시스템 호출로 제한
= 다른 방법으로는 커널에 들어오지 못하도록 컴퓨터 자원을 보호
시스템 호출 방법
• 프로그램에서 명령이나 서브루틴의 호출 형태로 호출
• 시스템에서 명령 해석기를 사용하여 대화 형태로 호출
디바이스 드라이버
디바이스 드라이버(Device Driver)
- 커널과 하드웨어의 인터페이스 역할을 수행
- 마우스 같은 표준화된 간단한 제품은 커널이 기본 드라이버로 가지고 운영함
- 그래픽카드와 같이 복잡하고 제품에 따라 기능이 서로 다른 특징을 갖는 경우 제작사가 별도로 드라이버를 제공
커널의 구조
커널의 핵심 기능
프로세스 관리
• 프로세스에 CPU를 배분
메모리 관리
파일 시스템 관리
• 데이터 저장을 위한 인터페이스를 제공
입출력 관리
• 필요한 입력과 출력 서비스를 제공
프로세스간 통신(IPC) 관리
• 공동 작업을 위한 각 프로세스간 통신 환경을 제공
네트워크 관리
특성
운영체제가 점점 더 다양한 하드웨어와 소프트웨어를 지원
= 커널 구조도 점점 복잡해 지고 있음
단일형 구조 커널
- 초창기의 운영체제 구조
- 커널의 핵심 기능을 구현하는 모듈들이 구분 없이 하나로 구성
장점
• 모듈 간의 통신 비용이 줄어들어 효율적인 운영이 가능
단점
• 복잡한 구조로 인해 버그나 오류 수정이 어려움
• 운영체제의 여러 기능이 상호 의존성이 있으므로 기능상의 작은 결함이 시스템 전반에 미침
• 다양한 환경의 시스템에 적용하기 어려움 = 호환성 부족(Incompatibility)
• 현대의 운영체제 : 매우 크고 복잡하기 때문에 완전 단일형 구조의 운영체제를 구현하기가 어려움
계층형 구조 커널
- 유사 기능을 가진 모듈을 하나의 계층으로 구현
- 계층 간의 통신을 통해 운영체제 서비스를 지원
마이크로 구조 커널
- 가장 기본적인 기능만 제공
• 기능 예: 프로세스 관리, 메모리 관리, 프로세스 간 통신 관리 등
- 커널의 각 모듈을 세분화
- 모듈 간의 정보 교환은 마치 프로세스 간 통신처럼 이루어짐
가상 머신
가상 머신(Virtual Machine)
가상 머신을 사용하면 응용 프로그램이 모두 동일한 환경에서 작동하는 것처럼 보임
운영체제와 응용 프로그램 사이에서 작동하는 중간 프로그램 (미들웨어: Middleware)
운영체제의 종류
유닉스의 개발과 확산
1969년 AT&T의 연구원으로서 멀틱스(Multics) 프로젝트의 결과물
멀틱스 프로젝트의 중간 산출물로 ‘유닉스(UNIX)’를 발표
유닉스의 뛰어난 기능으로 인해 현재까지 사용되고 있음
리눅스(Linux)의 개발
1991년에 리누스 톨바즈(Finland, University of Helsinki)에 의해 커널 개발
애플 II의 등장
애플의 전략:
• 기술을 발전시키는 것보다 사용자에게 편리함을 제공
• GUI와 같은 사용자 편의를 위한 인터페이스 기술 개발에 집중
윈도우의 출시
- 1995년 이후 응용프로그램에서 운영체제로 전환
- 마이크로소프트는 애플 Mac OS의 그래픽 사용자 인터페이스에서 영감을 받음
안드로이드
- 리눅스 커널을 기본 운영체제로 하며 스마트폰 또는 임베디드 장치를 위해 사용자 인터페이스 및 기타 유틸리티를 제공
- GNU의 리눅스를 사용하여 제작되었기 때문에 GPL을 따름
- 누구나 공짜로 사용할 수 있음
- 새로운 버전과 동시에 소스코드도 공개하기 때문에 누구나 수정 및 재배포가능
• 안드로이드는 구글에서 개발됨
• 스마트폰 제조사들은 대부분 안드로이드의 소스코드를 자사 제품에 맞게 수정하여 무료로 배포 중
컴퓨터 시스템 구조 - 기본 구성
하드웨어의 구성
컴퓨터의 구성
필수 장치
• 중앙처리장치(CPU), 주 메모리(대부분의 작업이 이루어 짐)
주변장치
• 입력장치, 출력장치, 저장장치
용어
- 중앙처리장치 = CPU, 주 프로세서(Main Processor)
- 주 메모리 = 메인 메모리(Main Memory) 또는 메모리
- 보조저장장치 = 저장장치 또는 데이터 스토리지
CPU와 주 메모리
CPU(Central Process Unit)
• 명령어를 해석하여 실행하는 장치
• 각종 연산을 수행
주 메모리(Main Memory)
• 작업에 필요한 프로그램과 데이터를 저장하는 장소
• 데이터의 접근 단위 : 워드(Word)
입·출력장치
입력장치
• 외부의 데이터를 컴퓨터에 입력하는 장치
• 예: 키보드, 마우스, 마이크, 스캐너 등
출력장치
• 처리 결과를 사용자가 원하는 형태로 출력하는 장치
• 예: 모니터, 스피커, 프린터 등
저장장치(디스크)
메모리보다 느리지만 저렴하고 용량이 큼
전원의 온·오프와 상관없이 데이터를 영구적으로 저장
느린 저장장치를 사용하는 이유 : 저장 용량에 비해 가격이 저렴
종류
• 자성(magnetic)을 이용하는 장치 : 카세트테이프, 플로피디스크, 하드디스크 등
• 레이저를 이용하는 장치 : CD, DVD, 블루레이디스크 등
• 메모리를 이용하는 장치 : USB 드라이브, SD 카드, SSD 등
메인보드(Main Board)
동일어: 마더보드(Mother Board)
CPU와 메모리 등 다양한 부품을 연결하는 커다란 판
다양한 장치들을 버스(bus)로 연결 - 버스는 데이터가 지나다니는 통로
그래픽카드, 사운드카드, 랜카드 등의 기능이 기본으로 탑재되거나, 별도 장착(daughter board)이 가능
시스템 아키텍처
대표적인 종류
- 폰노이만 아키텍처
- 하버드 아키텍처
폰노이만 아키텍처
- CPU, 메모리, 입출력 장치, 저장장치가 하나의 버스로 연결되어 있는 구조
- 명령어와 데이터를 위한 메모리 인터페이스가 하나임
- 명령어를 읽을 때 데이터를 읽거나 쓸 수 없음
- 프로그램은 하드디스크와 같은 외부 저장 장치에 기록
- 프로그램의 구동을 위해서는 기록된 데이터를 주 메모리(RAM)로 읽어와야 함
- 메모리의 효율적인 접근에 따라 시스템의 성능에 큰 영향을 미침
하버드 아키텍처
- 명령어를 위한 메모리 인터페이스와 데이터를 위한 메모리 인터페이스가 분리되어 있음
- 버스 시스템이 복잡하여 설계가 복잡함(단가 상승)
하드웨어 사양 관련 용어
클록(Clock)
- CPU의 속도와 관련된 단위
- 클록이 일정 간격으로 틱(tick)을 만들면 거기에 맞추어 CPU안의 모든 구성 부품이 작업을 수행함
- 틱(Tick) = 펄스(Pulse) = 클록 틱(Clock Tick)
헤르츠(Hz)
클록틱이 발생하는 속도를 나타내는 단위
• 1초에 클록틱이 한 번이면 1Hz,
• 1,000번이면 1kHz(1,000Hz)
• 3.4GHz는 1초에 틱이 3.4×109번 발생(34억)
시스템 버스
- 메모리와 주변장치를 연결하는 버스
- FSB(Front-Side Bus, 전면 버스)라고 함
CPU 내부 버스
- BSB(Back-Side Bus, 후면 버스)라고 함
CPU와 메모리의 속도
- CPU는 CPU 내부 버스(BSB)의 속도로 작동
- 메모리는 시스템 버스(FSB)의 속도로 작동
- 두 버스의 속도 차이로 인하여 작업이 지연될 수 있음 - 캐쉬(cache)로 해결
CPU의 구성과 동작
산술논리 연산장치(ALU: Arithmetic Logic Unit)
- 데이터의 덧셈, 뺄셈, 곱셈, 나눗셈 같은 산술 연산과 AND, OR 같은 논리 연산을 수행
제어장치(Control Unit)
- CPU에 작업을 지시
레지스터(Register)
- CPU 내에 데이터를 임시로 보관
버스(Bus)
- CPU내 구성요소들과의 데이터 전달을 위한 통로
CPU의 명령어 처리 과정*
int D2=2, D3=3, sum; sum=D2+D3;
- 위 코드를 어셈블리어로 바꾸면 다음과 같음

- 01행 : 메모리 100번지(D2)에 있는 값을 레지스터 2로 가져옴
- 02행 : 메모리 120번지(D3)에 있는 값을 레지스터 3으로 가져옴
- 03행 : 레지스터 2와 3에 저장된 값을 더한 결과를 레지스터 5에 저장
- 04행 : 레지스터 5의 값을 메모리 160번지(sum)에 저장

버스의 종류*

버스의 대역폭
한 번에 전달할 수 있는 데이터의 최대 크기
CPU가 한 번에 처리할 수 있는 데이터의 크기와 같음
CPU는 워드(word)단위로 데이터를 처리
• 예: 32bit CPU
– 메모리에서 데이터를 읽거나 쓸 때 한 번에 최대 32bit 처리
– 레지스터의 크기 : 32bit
– 버스의 대역폭 : 32bit
일반적으로 버스의 대역폭, 레지스터의 크기, 메모리에 한 번에 저장할 수 있는 데이터의 크기는 동일하게 설계
컴퓨터 시스템 구조 - 메모리 및 성능향상 기법
메모리의 종류
휘발성 메모리
DRAM(Dynamic RAM)
• 저장된 0과 1의 데이터가 일정 시간이 지나면 사라지므로 일정 시간마다 다시 재생시켜야 함
SRAM(Static RAM)
• 전력이 공급되는 동안에는 데이터를 보관할 수 있어 재생할 필요가 없음
SDRAM(Synchronous Dynamic Random Access Memory)
• 클록틱(펄스)이 발생할 때마다 데이터를 저장하는 동기식 DRAM
비휘발성 메모리
플래시 메모리(Flash Memory)
• SD 카드, USB 드라이브같이 전력이 없어도 데이터를 보관할 수 있는 저장장치
• SSD(Solid State Drive)
– 빠른 데이터 접근 속도, 저전력, 내구성이 HDD보다 좋음
롬(ROM)의 종류
마스크 롬(Mask ROM)
• 데이터를 지우거나 쓸 수 없음
PROM(Programmable ROM)
• 전용 기계를 이용하여 데이터를 한 번만 저장할 수 있음
EPROM(Erasable Programmable ROM)
• 데이터를 여러 번 쓰고 지울 수 있음
메모리 보호
메모리 보호의 필요성
현대의 운영체제는 시분할 기법을 사용하여 여러 프로그램을 동시에 실행
사용자(응용프로그램) 영역이 여러 개의 작업 공간으로 나뉨
메모리가 보호되지 않으면 다른 작업의 영역을 침범
• 오류 발생(정상동작 불가)
• 프로그램을 파괴하거나 데이터를 지울 수 있음
• 최악의 경우 운영체제 영역을 침범하여 시스템 마비도 가능
메모리 보호 방법
① 작업의 메모리 시작 주소를 경계 레지스터에 저장 후 작업
② 작업이 차지하고 있는 메모리의 크기, 즉 마지막 주소까지의 차이를 한계 레지스터에 저장
③ 사용자의 작업이 진행되는 동안 이 두 레지스터의 주소 범위를 벗어나는 지 하드웨어적으로 점검
④ 두 레지스터의 값을 벗어 나면 메모리 오류와 관련된 인터럽트가 발생
⑤ 메모리 영역을 벗어나서 발생한 인터럽트의 경우 운영체제가 해당 프로 그램을 강제 종료
부팅
부팅
컴퓨터에 전원을 인가
운영체제를 메모리에 적재(Loading)
운영체제의 초기화 수행
• 하드웨어 점검
• 각종 운영체제 모듈의 기능 구성
성능 향상 기법
버퍼(Buffer)
- 속도에 차이가 있는 두 장치 사이에서 그 차이를 완화하는 역할을 하는 장치
- 일정량의 데이터를 모아 옮김으로써 속도의 차이를 완화
스풀(Spool)
- CPU와 입출력장치가 독립적으로 동작하도록 고안된 소프트웨어적인 버퍼
[예] 프린트 스풀러
• 인쇄할 내용을 순차적으로 출력하는 소프트웨어로 출력 명령을 내린 프로그램과 독립적으로 동작
• 인쇄물이 완료될 때까지 다른 인쇄물이 끼어들 수 없으므로 프로그램 간에 배타적임
캐시(Cache)
메모리와 CPU 간의 속도 차이를 완화하기 위해 메모리의 데이터를 미리 가져와 저장해두는 임시 장소
• CPU와 주메모리 간 운영 클록(base clock)도 다름: BSB vs FSB
필요한 데이터를 모아 한꺼번에 전달하는 버퍼의 일종으로 CPU가 앞으로 사용할 것으로 예상되는 데이터를 미리 가져다 놓음
CPU가 특정 메모리 주소에 접근할 때, 캐시에 해당 데이터가 있으면 그 데이터가 바로 사용됨
캐시 히트(Cache Hit)*
• 캐시에 원하는 데이터를 찾음
• 그 데이터를 바로 사용
캐시 미스(Cache Miss)*
• 원하는 데이터가 캐시에 없을 때
• 메모리로 가서 데이터를 갖고 옴
캐시 적중률(Cache Hit Ratio)*
• 캐시 히트가 되는 비율
• 캐시 적중률이 높을 수록 더 빠른 처리가 가능
즉시 쓰기(Write Through)
• 캐시의 데이터가 변경되면 이를 즉시 메모리에 반영
• 메모리와의 빈번한 데이터 전송 = 성능 저하 발생
• 메모리에 최신 값이 유지되는 장점
지연 쓰기(Write Back)
• 주기적으로 변경된 내용을 메모리에 반영
• 카피백(Copy Back)이라고도 함
• 메모리와의 데이터 전송 횟수가 줄어들어 시스템의 성능이 향상됨
• 메모리와 캐시 데이터 사이의 데이터 불일치 가능성 존재
L1 캐시와 L2캐시
• 일반 캐시
– 명령어와 데이터의 구분 없이 모든 자료를 가져옴
– 메모리와 연결되기 때문에 L2(Level 2) 캐시라고 부름
• 특수 캐시
– 명령어와 데이터를 구분하여 가져옴
– CPU 레지스터에 직접 연결되기 때문에 L1(Level 1) 캐시라고 부름
저장장치의 계층 구조
개념
• 용량이 작고 빠른 저장장치를 CPU 가까운 쪽에 배치
• 용량이 크고 느린 저장장치를 반대쪽에 배치
• 효율적인 가격에 적당한 속도와 용량을 동시에 얻는 방법
이점
• CPU와 가까운 쪽에 레지스터나 캐시를 배치 = CPU가 작업을 빨리 진행
• 메모리에서 작업한 내용을 하드디스크와 같이 저렴하고 용량이 큰 저장장치에 영구적으로 저장할 수 있음
인터럽트
폴링 방식(Polling)
CPU가 직접 입출력장치에서 데이터를 가져오거나 내보내는 방식
CPU가 입출력장치의 상태를 주기적으로 검사
• 일정한 조건을 만족할 때 데이터를 처리
• 반복적인 모니터링 작업으로 인해 작업 효율이 떨어짐
인터럽트 방식(Interrupt)
입출력 관리자가 대신 입출력을 해주는 방식
CPU의 작업과 저장장치의 데이터 이동을 독립적으로 운영
• 시스템의 효율을 높임
데이터의 입출력이 이루어지는 동안 CPU가 다른 작업을 할 수 있음
인터럽트
- 입출력 관리자가 CPU에 보내는 이벤트 신호
인터럽트 번호
- 많은 주변장치 중 어떤 것에 이벤트가 발생되었는지를 CPU에 알려주기 위해 사용하는 번호
인터럽트 벡터
- 여러 개의 입출력 작업을 한꺼번에 처리하기 위해 여러 개의 인터럽트를 하나의 배열로 만든 것
인터럽트 방식의 동작 과정
① CPU가 입출력 관리자에게 입출력 명령을 보낸다.
② 입출력 관리자는 명령받은 데이터를 메모리에 가져다 놓거나 메모리에 있는 데이터를 저장장치로 옮긴다.
③ 데이터 전송이 완료되면 입출력 관리자는 완료 신호를 CPU에 보낸다.
직접 메모리 접근(DMA: Direct Memory Access)
- 입출력 관리자가 CPU의 허락 없이 메모리에 접근할 수 있는 권한
- 메모리는 CPU의 작업 공간이지만, 데이터 전송을 지시받은 입출력 관리자는 직접 메모리 접근권한이 있어야만 작업을 처리할 수 있음
메모리 매핑 입출력(MMIO: Memory Mapped I/O)
메모리의 일정 공간을 입출력에 할당하는 기법
사이클 훔치기
- CPU와 직접 메모리 접근(DMA)이 동시에 메모리에 접근하면 CPU가 양보함
- CPU의 작업 속도보다 입출력장치의 속도가 느리기 때문에 직접 메모리 접근에
양보하는 것 = 이러한 상황 : 사이클 훔치기(Cycle Stealing)
컴퓨터 시스템 구조 - 병렬 처리
병렬 처리의 개념
병렬 처리(Parallel Processing)
동시에 여러 개의 명령을 처리하여 작업의 능률을 올리는 방식
파이프라인 기법
하나의 코어에 여러 개의 스레드(Thread)를 이용하는 방식
슈퍼스칼라 기법
멀티코어 CPU를 이용해 여러 개(코어 개수)의 작업을 동시에 처리 하는 방식
병렬 처리 시 고려 사항
상호 의존성이 없어야 병렬 처리가 가능
각 명령이 서로 독립적이고 앞의 결과가 뒤의 명령에 영향을 미치지 않아야 함
각 단계별 처리 시간이 동일해야 함
- 오랜 시간이 걸리는 작업이 발생하면, 이 때문에 전체 작업이 밀림
- 단계별 시간의 차이가 크면 병렬 처리의 효과가 떨어짐
전체 작업 시간을 몇 단계로 나눌지 잘 따져보아야 함
병렬 처리의 깊이 N은 동시에 처리할 수 있는 작업의 개수를 의미
N이 커질수록 동시에 작업할 수 있는 작업의 개수가 많아짐 = 성능 향상
작업이 너무 많으면 각 단계마다 작업을 이동하고 새로운 작업을 불러오는 데 시간이 너무 오래 걸림 = 성능 저하
병렬 처리 기법
CPU에서 명령어가 실행되는 과정
① 명령어 패치(IF) : 다음에 실행할 명령어를 명령어 레지스터에 저장
② 명령어 해석(ID) : 명령어 해석
③ 실행(EX) : 해석한 결과를 토대로 명령어 실행
④ 쓰기(WB) : 실행된 결과를 메모리에 저장
파이프라인 기법
CPU의 사용을 극대화하기 위해 명령을 겹쳐서 실행하는 방법
파이프라인의 위험*
- 데이터 위험(Data Hazard)
- 제어 위험(Control Hazard)
- 구조 위험(Structural Hazard)
데이터 위험(Data Hazard)
• 데이터의 의존성 때문에 발생하는 문제
• 의존성을 갖는 데이터가 병렬처리되면 안 됨
• 해결 방법: 파이프라인의 명령어 단계를 지연하여 해결
제어 위험(Control Hazard)
• 프로그램 카운터 값을 갑자기 변화시켜 발생하는 위험
• 첫 명령어를 실행 후 다음 문장이 아닌, 다른 문장으로 이동하게 될 경우 후속 명령이 쓸모 없어짐
• 해결 방법: 분기 예측이나 분기 지연 방법으로 해결
구조 위험(Structural Hazard)
• 서로 다른 명령어가 같은 자원에 접근하려 할 때 발생하는 문제
• 명령어 A가 레지스터 RX를 사용하고 있는데 병렬 처리되는 명령어 B도 레지스터 RX를 사용해야 한다면 서로 충돌
• 구조 위험은 해결하기 어렵다고 알려져 있음
슈퍼스칼라 기법(Super-Scalar)
- 파이프라인을 처리할 수 있는 코어를 여러 개 구성하여 복수의 명령어가 동시에 실행되도록 하는 방식
- 대부분은 파이프라인 기법과 동일하지만 코어를 2개 구성하여 각 단계에서 동시에 실행되는 명령어가 2개라는 점이 다름
슈퍼파이프라인 기법(Super-Pipeline)
- 파이프라인의 각 단계를 세분하여 한 클록 내에 여러 명령어를 처리
- 한 클록 내에 여러 명령어를 실행하면 다음 명령어가 빠른 시간 안에 시작될 수 있어 병렬 처리 능력이 높아짐
슈퍼파이프라인 슈퍼스칼라 기법(Super-Pipelined Super-Scalar)
슈퍼파이프라인 기법을 여러 개의 코어에서 동시에 수행하는 방식\
VLIW 기법(Very Long Instruction Word)
CPU가 병렬 처리를 지원하지 않을 경우 소프트웨어적으로 병렬 처리를 하는 방법
동시에 수행할 수 있는 명령어들을 컴파일러가 추출하고 하나의 명령어로 실행
• 일반적인 병렬 처리 기법들에 비해 동시에 처리하는 명령어의 개수가 적음
• 컴파일 시 관련 처리 명령이 생성됨
CISC와 RISC
CISC
- 4싸이클에 1개의 명령문을 처리함(가변)
- 명령어가 많음
- 메모리 참조 연산이 상대적으로 많음
- 레지스터 개수가 적음
RISC
- 4싸이클에 4개의 명령문을 처리함(고정)
- 컴파일러의 최적화가 필요함
- Load/Store 방식으로 메모리 참조 연산의 개수가 적음
- 레지스터 개수가 많음
무어의 법칙과 암달의 법칙
무어의 법칙(Moore’s law)*
- CPU의 속도가 24개월마다 2(1.8)배 빨라진다는 내용
- 초기의 CPU에만 적용되며 지금은 그렇지 않음
암달의 법칙(Amdahl’s law)*
- 컴퓨터 시스템의 일부를 개선할 때 전체 시스템에 미치는 영향과의 관계를 수식으로 나타낸 법칙
- 이 법칙에 따르면 주변장치의 향상 없이 CPU의 속도를 2GHz에서 4GHz로 늘리더라도 컴퓨터의 성능이 2배 빨라지지 않음
프로세스 관리 - 프로세스의 개요
프로세스의 개념
프로그램(program)
저장장치에 기록되어 있는 정적인 소프트웨어
실행 가능한 소프트웨어
- 컴파일 언어 기반의 소프트웨어일 경우 main() 함수가 반드시 존재하는 소프트웨어
- main() 함수가 없다면, 이는 라이브러리(library) 등으로 분류
프로세스(process)
- 메모리에 로드(load)되어 주기적으로 CPU에 의해 처리되는 소프트웨어
- 주기적으로 CPU를 점유
- 프로세스 제어 블록(PCB: Process Control Block 또는 Process Status Block 자료구조) 할당
- 동음어: 태스크(task), 잡(job)
프로세서(processor)
- 명령을 실행(처리)하는 하드웨어
- 예: CPU(Central Process Unit), MPU(Micro Process Unit), MCU(Micro Control Unit), AP(App
Processor) 등
프로세스 관리
관리 기능
- 프로세스 등록(create)
- 프로세스 소멸(destroy)
- 프로세스의 상태(status) 정의와 천이(transaction)
- 문맥 교환(Context Switching) 및 스케줄링(Job Scheduling)
- 인터럽트(interrupt) 처리
프로세스로 전환
프로세스와 프로그램의 관계
프로그램이 프로세스로 변환
• 프로세스 생성 및 시작을 의미
• 운영체제로부터 프로세스 제어 블록(PCB)을 얻는다는 뜻
• PCB : Process Control Block
프로세스 종료
• 해당 프로세스 제어 블록이 폐기된다는 뜻
프로세스 제어 블록
PCB 정의 및 역할
운영체제가 각 프로세스 관리하기 위해 정의한 자료 구조
• 프로세스 구분자(PID) : 각 프로세스를 구분하는 구분자(ID)
• 메모리 관련 정보 : 프로세스의 메모리 위치 정보
• 각종 중간값 : 프로세스가 사용했던 중간값(문맥 교환 때 백업한 자료들)
각 프로세스는 고유의 PCB를 가짐
프로세스 생성 시 운영체제에 의해 만들어지고 프로세스 종료 시 폐기
구성
포인터 :
• 대기 상태에 있을 경우 입출력 요구 대상 프로세스끼리 연결리스트로 관리
프로세스 상태 :
• 생성, 준비, 실행, 대기,보류 상태 등을 저장
프로세스 구분자(식별자) :
• 프로세스를 구분하기 위한 ID
프로그램 카운터 :
• 다음에 실행될 명령어의 위치값
프로세스 우선순위 :
• 실행 순서를 결정을 위한 우선순위
각종 레지스터 정보 :
• 실행되는 중에 사용하던 레지스터 값
메모리 관리 정보 :
• 프로세스의 메모리 위치 정보
• 메모리 보호를 위해 사용하는 경계 레지스터 값과 한계 레지스터 값 등
할당된 자원 정보 :
• 입출력 자원이나 오픈 파일 등에 대한 정보
계정 정보 :
• 계정 번호, CPU 할당 시간, CPU 사용 시간 등
PPID와 CPID :
• PPID: 부모 프로세스 식별자
• CPID: 자식 프로세스 식별자
프로세스의 상태
네 가지 상태
- 생성 상태(new) : 메모리에 적재되어 프로세스로 변환될 준비가 된 상태
- 준비 상태(ready) : CPU 점유를 위해 기다리는 상태
- 실행 상태(running) : CPU를 점유한 상태
- 완료 상태(end/terminate) : 프로세스 제어 블록이 사라진 상태
천이를 위한 대표 행위(두 가지)
- 디스패치(dispatch) : 대기 상태에서 실행 상태로 변하는 과정
- 타임아웃(timeout) 또는 인터럽트(interrupt) : 실행상태에서 준비 상태로 진입을 위한 이벤트
다섯 가지 상태
- 네 가지 상태 + 1의 구조
- 대기 상태(waiting / blocking) 추가
보류 상태를 포함한 프로세스 상태

프로세스 상태 세부
생성 상태
• 메모리에 적재되어 프로세스로 변환될 준비가 된 상태
• 새로운 프로세스 제어 블록(PCB)이 운영체제에 등록됨
• 생성된 프로세스는 준비 상태에서 자기 순서를 기다림
준비 상태
• CPU를 점유하기 위해 대기 중인 상태
- 대부분의 프로세스가 이 상태에 있음
• PCB는 준비 큐에서 기다리며 CPU 스케줄러에 의해 관리
실행 상태
• 프로세스가 CPU를 점유하고 있는 상태
• 자신에게 주어진 시간(타임 슬라이스) 동안만 CPU를 점유
• 타임아웃되면 준비 상태로 전환
• 작업이 완료되면 프로세스 종료(소멸, PCB 삭제)
• 입출력 요청이 있으면 대기상태로 진입
- 입출력이 완료되면 준비 상태로 진입\
대기 상태
• 입출력이 완료될 때까지 기다리는 상태
• 입출력 완료 인터럽트가 발생하면 입출력장치 별 큐에서 빠져나와 준비 상태로 진입
완료 상태
• 프로세스가 종료되는 상태
• 메모리내 코드와 데이터를 메모리에서 삭제
• PCB 폐기
보류 상태
• 프로세스가 준비 또는 대기 상태에서 한동안 변화가 없을 때 보류 상태로 전환됨
• 다음과 같은 경우에 보류 상태가 됨
- 실행 메모리 공간이 부족할 때
- 프로그램에 오류가 있어서 실행을 계속 미루는 상황
- 바이러스와 같이 악의적인 공격(잘못된 자원 접근을 시도)을 하는 프로세스라고 판단될 때
- 간헐적으로 실행되는 프로세스로 우선 순위에서 뒤에 있을 때
- 입출력을 기다리는 프로세스의 입출력이 계속 지연될 때
- 예: 웹브라우저에서 응답없음 대기상황
프로세스 기타 상태
좀비(zombie) 상태
• 운영체제가 프로세스의 소멸(폐기)를 못한 프로세스
• 실행 상태 진입을 하지 않으며 메모리에 잔존
정지(휴식) 상태
• 프로세스가 작업을 일시적으로 쉬고 있는 상태
• 유닉스 쉘 프롬프트(prompt)에서 프로세스 동작 중에 [Ctrl + Z]를 누르면 볼 수 있는 상태
• 단, [Ctrl + C]를 누르면 프로세스는 강제 종료가 됨
프로세스 관리 - 스레드
스레드의 개념
스레드의 정의
CPU 스케줄러가 CPU에 전달하는 일들 중 하나
스레드(thread): 프로세스의 최소 단위
• 하나의 프로세스에는 여러 개의 스레드를 구성할 수 있음
멀티 태스크와 멀티 스레드의 차이
멀티 태스크(Multi-tasks)
• 하나의 업무수행을 위해 여러 개의 프로세스들로 구성 시키는 것
• 구현을 위해 프로세스간의 통신기법(IPC: Inter-Process Communication 기술이 필요)
멀티 스레드(Multi-threads)
• 하나의 프로세스에 여래 개의 스레드로 구성 시키는 것
• 하나의 프로세스를 공유하기 때문에, 모든 스레드는 전역 메모리 영역 등을 공유함
스레드 제어 블록
TCB(Thread Control Block)
- 스레드의 정보를 저장
- PCB에는 TCB 리스트를 포함
- 프로세스와는 달리 스레드 간의 보호는 없음
• 스레드 간의 모든 자원은 공유됨
- TCB의 주 내용
• 실행 상태: 레지스터, 프로그램 카운터, 스택 포인터
• 스케줄링 정보: 상태(실행, 준비, 대기 등), 우선순위 등
• 계정 정보
• 스케줄링 큐를 위한 다양한 포인터
• PCB를 위한 주소 포인터
멀티 스레드/태스킹/프로세싱
멀티 스레드
- 프로세스 내 작업을 여러 개의 스레드로 분할
멀티 태스킹
- 운영체제가 CPU에 작업을 줄 때 시간을 잘게 나누어 배분하는 기법
멀티 프로세싱
- CPU를 여러 개 사용하여 여러 개의 스레드를 동시에 처리하는 작업 환경
CPU 멀티 스레드
- 파이프라인 기법을 이용
- 동시에 여러 스레드를 처리하도록 만든 병렬 처리 기법
• 멀티 스레드: 운영체제가 소프트웨어적으로 프로세스를 작은 단위의 스레드로 분할
• CPU 멀티스레드 : 하드웨어적인 방법, 하나의 CPU에서 여러 스레드를 동시에 처리
멀티스레드의 장점
- 응답성 향상
- 자원 공유
- 다중 CPU 지원
- 효율성 향상
멀티스레드의 단점
자원 공유로 인한 오류정보 또한 공유되어 전체 프로세스에 영향을 줌
※ 하이퍼 스레딩 기술(Hyper-Threading Technology)
인텔(Intel)이 CPU 멀티 스레딩을 위해 구현한 기술
물리적인 코어 하나를 가상의 논리적인 코어 두 개로 할당하는 기술
운영체제는 다중 코어(멀티 프로세서)로 인식
• 동시에 다량의 프로세스(또는 스레드) 동작
• 결과: 프로세스의 대기시간 단축 및 성능 향상 발생
멀티 스레드 모델
종류
사용자 레벨 스레드
• 사용자 프로그램(응용프로그램 등)에 의해 구현된 일반적인 스레드
커널 레벨 스레드
• 커널이 내부적인 동작을 위해 사용되는 스레드
• 커널이 프로세스를 위한 스레드를 직접 생성 및 관리
멀티 레벨 스레드
• 사용자 스레드와 커널 스레드의 혼합
사용자 스레드
- 커널내 하나의 스레드와 사용자 프로세스 내에 여러 개의 스레드가 연결(1 to N 모델)
- 라이브러리가 직접 스케줄링 = 문맥 교환이 필요 없음
- 커널 스레드가 입출력 작업을 위해 대기 상태에 들어가면 모든 사용자 스레드가 대기하게 됨
- 한 프로세스의 타임 슬라이스를 여러 스레드가 공유하기 때문에 여러 개의 CPU를 동시에 사용할 수 없음
커널 스레드
- 하나의 사용자 스레드가 하나의 커널 스레드와 연결(1 to 1 모델)
- 하나의 스레드가 대기 상태에 있어도 다른 스레드는 작업을 계속할 수 있음
• 독립적으로 스케줄링이 되므로 특정 스레드가 대기 상태에 들어가도 다른 스레드는 작업을 계속할 수 있음
- 커널 레벨에서 모든 작업을 지원하기 때문에 멀티 CPU를 사용할 수 있음
- 커널의 기능을 사용하므로 보안에 강하고 안정적으로 작동
- 문맥 교환 시 오버헤드 발생 = 느리게 작동
멀티레벨 스레드
- 사용자 스레드와 커널 스레드를 혼합한 방식(M to N 모델)
- 커널 스레드가 대기 상태에 들어가면 다른 커널 스레드가 대신 작업을 하여 사용자 스레드보다 유연하게 작
업을 처리할 수 있음
- 커널 스레드를 같이 사용하기 때문에 여전히 문맥 교환 시 오버헤드가 있어 사용자 스레드만큼 빠르지 않음
프로세스 관리
실습환경 구축
가상 머신(Virtual Machine)
- 게스트 운영체제의 동작 환경을 제공하는 가상의 하드웨어 환경을 제공
- 실습용 가상 머신 : VirtualBox
운영체제
- 리눅스 배포판을 통한 운영체제 기능을 실험
- 실습용 운영체제 : Debian Linux (버전: 11.5)
• 데이반 리눅스계열로 각종 해킹 관련 툴들이 포함된 리눅스 배포판
실습을 위한 환경 설정
쉘 변경
• 명령어: chsh
프로세스 상태 제어 실습
실습 준비
가상머신: VirtualBox
운영체제: 데비안 리눅스(Debian Linux)
정지(휴식) 상태 실습
명령어: ps
• 프로세스들에 대한 상태정보를 표시
명령어: kill
• 지정한 프로세스에게 시그널을 전송
• 시그널 번호는 앞에 ‘-’문자를 붙임
• 시그널의 리스트는 ‘kill – l’명령을 통해 확인 가능
1. 두 개의 터미널 창 생성
2. 한 곳(A창)에서는 “sleep 1000” 명령 실행
3. 다른 창(B창)에서는 “ps f”명령을 통해 프로세스 상태 파악
4. B창에서 “kill -19 [sleep에 해당하는 PID]”를 입력
5. B창에서 “ps f”명령을 통해 프로세스 상태 다시 파악
6. B창에서 “kill -18 [sleep에 해당하는 PID]”를 입력
7. B창에서 “ps f”명령을 통해 프로세스 상태 파악
문맥 교환
작업의 전환
작업과 이를 위한 환경을 모두 바꾸는 것
문맥 교환(Context Switching)
- CPU를 차지하던 프로세스를 옮기고 새로운 프로세스를 실행
- 직전 작업 정보들을 모두 PCB를 통해 백업
- 원복 시 기록된 PCB 백업정보들을 재활용
문맥 교환 절차

프로세스의 구조
메모리내 프로세스 구조
- 코드 영역(Code/Text/Instruction Area)
- 데이터 영역(Data Area)
- 스택 영역(Stack Area)
- 힙 영역(Heap Area)
코드 영역(Code/Text/Instruction Area)
• 프로그램 명령들이 기술된 곳
• 읽기 전용
데이터 영역(Data Area)
• 코드가 실행되면서 사용하는 변수나 파일 등의 각종 데이터를 모아놓은 곳
• 읽기와 쓰기 가능
스택 영역(Stack Area)
• 운영체제가 프로세스를 실행하기 위해 부수적으로 필요한 데이터를 모아놓은 곳
• 함수를 호출하면 함수를 수행하고 원래 프로그램으로 되돌아올 위치를 이 영역에 저장
• 운영체제가 사용자의 프로세스를 작동하기 위해 유지하는 영역
• 사용자에게는 보이지 않음
힙 영역(Heap Area)
• 동적으로 생성한 데이터 영역
• 주로 malloc이나 new 명령에 의해 생성됨
프로세스 생성과 복사
fork() 시스템 함수
- 실행중인 프로세스로부터 새로운 프로세스를 생성
- 자신과 동일한 프로세스를 자식 프로세스로 생성
- 함수의 결과값을 통해 자신이 부모인지 자식인지를 알 수 있음
• 부모: 자식프로세스의 ID
• 자식: 0
fork() 동작 과정
- PCB를 포함한 부모 프로세스 영역의 대부분(데이터, 힙, 스택 영역)이 자식 프로세스에 복사되어 새로운 프로세스가 만들어짐
• 새로운 PCB가 생성되어 내용물이 상속됨
- 단, PCB의 내용 중 다음이 변경됨
• 프로세스 구분자(PID)
• 메모리 관련 정보
• 부모 프로세스 구분자(PPID)
• 자식 프로세스 구분자(CPID) 등
fork() 사용의 장점
프로세스의 생성 속도가 빠름
• 이미 메모리에 적재된 프로세스를 기반으로 새로 만들어지기 때문
추가 작업 없이 자원을 상속할 수 있음
시스템 관리를 효율적으로 할 수 있음
• 계층형 구조
• 부모-자식 관계의 구조 때문임
프로세스의 계층 구조
유닉스의 프로세스 계층 구조
- 유닉스의 모든 프로세스는 init 프로세스의 자식이 되어 트리 구조를 이룸
- ps명령을 통해 확인할 경우 init가 1번으로 할당됨을 확인해 볼 수 있음
장점
- 체계화된 프로세스들에 대한 관리가 가능
- 로그인을 위한 프로세스의 경우, 사용자별 fork()를 수행하면되므로 메모리 중복(코드영역)을 최소화 할 수 있음
- 재사용이 용이
- 자원 회수가 쉬움
• 상하 관계로 인해 프로세스의 관리 및 호출 주체를 파악하기 쉬움
고아(orphan) 프로세스
- 부모 프로세스가 자식보다 먼저 죽는 경우
- 계층적 구조에서 따로 떨어져 있음
스케줄링 및 IPC - 스케줄링 개요
스케줄링 개요
개념
프로세스들에 대하여 CPU에 할당 기회를 결정하고 수행하는 과정
프로세스가 작업을 처리하기 위해 CPU 할당을 위한 일정을 처리
목적
모든 프로세스들에게 공정하게 배정 - 공평성
단위 시간당 최대한 많이 처리 - 처리율 극대화
- 빠른 응답
- 오버헤드 최소화
- 프로세스 무한대기 최소화
필요성
작업(프로세스)은 주어진 일을 수행하기 위해 다양한 자원(resource)을 사용
- 자원 예: CPU, memory, storage, network, file, I/O etc.
- 자원의 특징 : 유한함
CPU는 작업(프로세스) 단위로 처리
작업의 개수가 많아지면 자원들을 선점하기 위한 경쟁이 필요
작업 간의 효율적인 자원의 할당 및 공유를 위한 관리자가 필요 = 스케줄러(Scheduler)
스케줄링 정책
정해진 시간(time slice, time slot)에 프로세서를 점유할 프로세스를 선택
고려사항
- 최대의 처리량 = 프로세서 활용도 극대화
- 최소 지연시간
- 무기한 연기(대기)를 방지(공평성)
- 요청 데드라인 전에 완료
스케줄링의 목표

스케줄링 단계

상위단계 스케줄링(High Level Scheduling)
= 장기/작업/승인 스케줄링(long-term/job/admission scheduling)
시스템에 부담이 되지 않도록 전체 작업 수를 조절
어떤 작업을 시스템이 받아들일지 또는 거부할지를 결정
실행 가능한 프로세스의 총 개수를 정의
중간단계 스케줄링(Middle Level Scheduling)
중지(suspend) - 활성화(active) 상태 전환
활성화된 프로세스 조절 = 과부하를 해소
저수준 스케줄링의 부담을 완충하는 역할
하위단계 스케줄링(Low Level Scheduling)
= 단기 스케줄링(short-term scheduling)
짧은 시간에 처리
프로세스를 CPU에 할당
프로세스를 대기상태로 전환
선점형/비선점형 스케줄링
선점형 스케줄링(Preemptive Scheduling)
운영체제가 필요하다고 판단하면 실행 상태에 있는 프로세스의 작업 중단
다른 프로세스가 프로세서를 쟁취할 수 있음
- 새로운 작업을 시작할 수 있는 방식
하나의 프로세스가 CPU를 독점할 수 없음
- 빠른 응답이 가능
대화형 시스템이나 시분할 시스템에 적합
대부분의 저수준 스케줄러가 이 방식을 사용
비선점형 스케줄링(Non-Preemptive Scheduling)
한 프로세스가 CPU를 사용하면 종료 또는 자발적으로 나올 때까지 다른 프로세스는 대기
- 프로세스가 스스로 양보
과거의 일괄 작업 시스템에서 사용하던 방식
장점
- 선점형 스케줄링보다 스케줄러의 작업량이 적음
- 문맥 교환에 의한 프로세서 및 시간적인 낭비 감소
단점
- 덩치가 큰 프로세스는 CPU 사용이 길기 때문에, 타 프로세스의 대기시간을 길게 만듦
전체 시스템의 처리율이 떨어짐
전면/후면 프로세스
전면 프로세스(Foreground Process)
- GUI의 경우 운영체제 화면에서 맨 앞에 놓인 활성화 상태의 프로세스
- 현재 입력과 출력을 사용하는 프로세스
- 사용자와 상호작용이 가능 = 상호작용 프로세스
후면 프로세스(Background Process)
- 사용자와 상호작용이 없는 프로세스
- 사용자의 입력 없이 작동 (일괄 작업 프로세스라고도 함)
- 전면 프로세스 보다 우선순위가 낮음
실습
- 전면/후면 전환
- 관련 명령어:
• [Ctrl + Z] : 정지
• jobs : 동일 쉘내 작업들 출력
• fg : 전면으로 전환(Run상태 활성)
• bg : 후면으로 전환(Run상태 활성)
스케줄링 및 IPC - 스케줄링 기법
스케줄링 평가 방법
CPU 사용률(%)
- 전체 시스템의 동작 시간 중 프로세스들이 CPU를 사용한 비율을 측정
- 높을 수록 운영체제의 성능이 좋음

처리량
- 단위 시간당 작업을 마친 프로세스의 수
- 수치가 클수록 좋은 알고리즘
시간
대기 시간 : 프로세스가 생성된 후 실행되기 전까지 대기하는 시간
- 예: 실행 파일 더블클릭 후 실제 구동시작 시간의 차이
응답 시간 : 첫 작업을 시작한 후 첫 번째 출력(반응, response, feedback)이 나오기까지의 시간
- 예: 실행프로그램 UI 생성된 시간
실행 시간 : 프로세스 작업이 시작된 후 종료되기까지의 시간
- 예: 실행프로그램의 동작시간
반환 시간 : 대기 시간을 포함하여 실행이 종료될 때까지의 시간
- 예: 실행프로그램의 종료시간(전체 시간)

평균 대기 시간


FCFS 방식
FCFS
- First Come First Served : 선입선출
- 큐에 도착한 순서대로 CPU를 할당
FCFS의 평균 대기시간 계산

FCFS 평가
만약 처리 시간이 긴 프로세스가 CPU를 차지
= 다른 프로세스들은 하염없이 기다려 시스템의 효율성이 떨어짐
만약 작업 중인 프로세스가 입출력 작업을 요청
= CPU가 작업하지 않고 쉬는 시간이 많아져 작업 효율이 떨어짐
SJF 방식
SJF
- Shortest Job First : 최단 작업 우선
- 준비 큐에 있는 프로세스 중에서 실행 시간이 가장 짧은 작업부터 CPU를 할당
- 콘보이 효과를 완화하여 시스템의 효율성을 높임

SJF의 평균 대기시간 계산

SJF의 단점
- 운영체제가 프로세스의 종료 시간을 정확하게 예측하기 어려움
- 작업 시간이 길다는 이유만으로 계속 뒤로 밀려 공평성이 현저히 떨어짐 = 아사(starvation) 현상
아사 해결 방법
- 에이징(Aging, 나이 먹기)
- 순서를 양보할 때마다 나이를 한 살씩 먹임
- 프로세스가 양보할 수 있는 상한선을 정함
HRN 방식
HRN
- Highest Response Ratio Next : 최고 응답률 우선
- SJF 스케줄링에서 발생할 수 있는 아사 현상을 해결하기 위해 만들어진 비선점형 알고리즘
- 대기 시간과 CPU 사용 시간을 고려하여 스케줄링을 하는 방식
- 여전히 공평성이 위배되어 많이 사용되지 않음

HRN의 평균 대기시간 계산
① 대기시간 0을 먼저 채택
② 우선순위(가중치)를 추출
③ 우선순위 순으로 프로세스를 나열(가중치가 높은 값이 먼저 채택)

라운드 로빈 방식
라운드 로빈 스케줄링의 동작 방식
- 한 프로세스가 할당받은 시간(타임 슬라이스, 타임 슬롯) 동안 작업
- 작업을 완료하지 못하면 준비 큐의 맨 뒤로 이동 전환
- 다시 자기 차례를 기다림
- 선점형 알고리즘 중 가장 단순하고 대표적인 방식
- 프로세스들이 작업을 완료할 때까지 계속 순환

타임 슬라이스가 큰 경우
- 하나의 작업이 끝난 뒤 다음 작업이 시작
- FCFS 스케줄링과 다를 게 없음
타임 슬라이스가 작은 경우
- 문맥 교환이 너무 자주 일어남
- 문맥 교환에 시간을 너무 많이 소모 = 프로세스의 CPU 점유 시간을 단축(성능저하 발생)
SRT 방식
SRT
- 라운드 로빈 + SJF(Shortest Job First)
- CPU의 할당은 남은 작업 시간이 가장 적은 프로세스를 선택
- 현재 실행 중인 프로세스와 큐에 있는 프로세스의 남은 시간을 주기적으로 계산
- 프로세스의 종료 시간을 예측하기 어렵고 아사 현상 발생

기타: 에디터 및 컴파일
파일 내용 보기 명령들
명령어: cat [파일명]
지정한 파일의 내용을 화면에 출력
명령어: more [파일명]
지정한 파일의 내용을 화면에 출력 / 화면 단위로 출력(페이지 넘김: 스페이스바키)
명령어: tail [-###] [파일명]
지정한 파일에 대하여 뒤에서 ###(숫자)의 행만큼 출력
명령어: head [-###] [파일명]
지정한 파일에 대하여 앞에서 ###(숫자)의 행만큼 출력
텍스트 파일 에디터
PICO 에디터
- Nano 에디터라고도 함(v4.0부터 명명 nano로 바뀜)
- 단순한 형태의 파일 편집 기능을 제공
- 리눅스계열의 다양한 배포판에서 기본 탑재된 프로그램
명령어: pico {파일명}
- 저장: [Ctrl + O]
- 끝내기: [Ctrl + X]
VI 에디터(editor)
리눅스/유닉스에서는 일반적으로 VI 에디터가 가장 많이 쓰임
Bill Joy에 의해 BSD 유닉스용으로 처음 개발
대부분의 유닉스계열의 운영체제는 VI가 설치되어 있음
- VI의 사용을 익히는 것을 강력히 추천
단, 사용법을 익히는데 다소 시간이 걸리는 문제가 있음
명령어: vi {파일명}
- 저장: “:w” (명령모드에서 실행)
- 끝내기: “:q” (명령모드에서 실행)

GCC
컴파일
- 텍스트 또는 오브젝트 파일을 기계어로 변환
- 상용 UNIX에서는 cc라는 명령어를 사용
- GNU기반의 UNIX(리눅스 포함)에서는 gcc를 사용
- 명령어: gcc [파일명.c…] {-o 생성파일} {-l라이브러리}
파일의 확장자에 따른 처리

GCC 대표 옵션

스케줄링 및 IPC - IPC
프로세스 간 통신의 개념
정의
IPC : Inter-Process Communication
프로세스간 데이터를 공유하기 위한 방법
운영체제는 프로세스의 관리 및 각각의 동작을 보호
- 프로세스는 자신의 할당메모리 영역 외에는 접근 불가
- 타프로세스의 영역을 독단적으로 접근할 수 없음
프로세스간 통신을 위해 운영체제는 몇가지 자원을 제공
- 예: 시그널, 인터럽트, 공유 파일, 파이프, 공유메모리, 메시지큐 등
프로세스간 통신(IPC)
프로세스 내부 데이터 통신
- 프로세스 내 스레드간 통신 – 스레드는 전역 변수나 파일을 이용하여 데이터를 공유
프로세스 간 데이터 통신
- 같은 컴퓨터(동일 호스트)에 있는 프로세스간 통신
- 공용 파일 또는 운영체제가 제공하는 자원을 이용
네트워크를 이용한 데이터 통신
- 여러 컴퓨터가 네트워크로 연결되어 있을 때 통신
- 소켓을 이용한 데이터 공유
IPC 기법
종류
- 시그널
- 인터럽트
- 공유 파일
- 파이프
- 공유메모리
- 메시지큐
시그널(Signal)
운영체제는 프로세스를 관리하기 위한 시그널을 정의
시그널을 수신한 프로세스는 그에 맞는 행위를 수행
- 예1: 9(SIGKILL)는 프로세스를 강제 종료
- 예2: 14(SIGALRM)은 잠들어있는 프로세스를 깨움
인터럽트
이벤트 발생에 따른 처리를 위한 방식
프로세스가 동작 중 인터럽트가 발생하면 해당 기능을 수행
공유 파일
서로 다른 프로세스가 동일한 파일을 공유하여 사용하는 방식
프로세스 처리 성능은 기록 장치의 읽기/쓰기 속도에 영향을 받음
파이프
A 프로세스의 출력을 B프로세스의 입력으로 처리
실습 예: 특정프로그램의 출력 결과를 입력을 받아서 출력
공유메모리
운영체제에서 별도로 할당해준 공유 영역을 활용
각 응용프로그램을 해당 영역을 포인터로 접근
공유메모리 확인 명령: ipcs
메시지큐
큐(Queue) 방식으로 데이터를 접근
큐는 행위에 따라 En-queue와 De-queue로 분류
- En-queue는 큐에 데이터를 삽입
- De-Queue는 큐에서 데이터를 추출
공유메모리 실습
관련 명령어: ipcs, ipcmk, ipcrm
- Ipcs : IPC관련 운영체제내 상태를 확인
- Ipcmk : IPC관련 자원 생성
- Ipcrm : IPC관련 자원 삭제
방향성에 따른 분류
단방향 통신
- 한쪽 방향으로만 데이터를 전송할 수 있는 구조
- 대표적 예: 파이프(PIPE) 기법이 있음
양방향 통신
- 데이터를 동시에 양쪽 방향으로 전송할 수 있는 구조
- 대표적 예: 소켓 통신
반양방향 통신
- 양쪽 방향으로 전송이지만 동시 전송은 불가
- 특정 시점에 한쪽 방향으로만 전송할 수 있는 구조
- 대표적 예: 메시지 큐, 공유메모리
동시성에 따른 분류
대기가 있는 통신
동기화를 지원하는 통신 방식
데이터를 받는 쪽은 데이터가 도착할 때까지 자동 대기 상태(블록킹, Blocking)
대기가 없는 통신
동기화를 지원하지 않는 통신 방식
다른 작업을 하는 중에 데이터가 수신되면 처리
- 인터럽트(Interrupt, 이벤트) 처리 방식
- 폴링(Polling) 처리 방식
교착 및 기아 상태 - 임계 구역
임계 구역
Critical Area
- 또는 “임계 영역”이라 함
- 공유 자원에 대하여 프로세스(멀티스레드 포함)들의 동시 접근에 한계가 있는 영역
- 임계 구역을 접근할 때에는 반드시 가용 상태를 확인해야 함
프린터 예시
- 만약 프린터장치가 프로세스들의 동시 접근을 허용하게 된다면,
- 프로세스들에 의한 출력 요청 명령 들로 인해 기대 외의 결과물이 나오게 됨
공유 메모리 사용 예시
*result의 값은?

임계 구역 해결 조건
상호 배제(mutual exclusion)
한 프로세스가 임계 구역에 들어가면 다른 프로세스는 그곳에 들어갈 수 없음
한정 대기(bounded waiting)
어떤 프로세스도 무한 대기하지 않아야 함
진행의 융통성(progress flexibility)
다른 프로세스의 진행을 방해해서는 안 됨
세마포어 - Semaphore
임계 구역 접근을 위해 On/Off 표시등(lamp)을 운영
- On 상태 : 사용 중
- Off 상태 : 사용 가능
임계 구역을 접근하는 프로세스들은 이 표시등을 모니터링(반복 수행)
가용상태(Off 상태)이면, 자신이 On시키고 접근
모니터
Monitor
- 공유 자원을 내부로 숨김
- 외부 접속을 차단
- 인터페이스를 통해 공유 자원 갱신 및 데이터 추출
작동 원리
- 요청받은 작업을 모니터 큐에 저장
- 시스템은 모니터 큐의 데이터를 순서대로 처리
- 결과만 해당 프로세스에 알려줌

교착 및 기아 상태 - 교착 상태
교착 상태
Dead Lock
2개 이상의 프로세스가 서로 다른 프로세스의 작업이 끝나기만 기다리며 작업을 더 이상 진행하지 못하는 상태
병렬처리 기술과 자원 공유에 따라 발생된 부작용 중의 하나
- 여러 프로세스가 작업을 진행하다 보니 자연 발생적으로 일어나는 문제
아사(기아) 현상 : 특정 프로세스의 작업이 끊임없이 지연되는 문제
교각 공유 예
- 교각을 공유 자원(Resource)에 비유
- 교착상태가 발생하면 한쪽의 차가 후진을 해줘야 해결되는 상황
- 기아상태에 빠질 수 있음
- 대부분의 운영체제에서 교착상태를 완전히 예방해 주지는 못함

프로세스의 운영체제 자원의 이용 방식
운영체제는 프로세스에게 공유될 모든 자원들을 관리
- 프로세스의 자원 할당을 관리
- 각 자원에 대한 점유 상태 및 가용 상태 관리
모든 자원은 운영체제가 제공하는 시스템함수의 호출로 접근
• 요청(Get / Open)
– 자원의 접근(할당)을 요청
– 이미 사용 중이면 대기
• 사용(Hold / Read or Write)
– 할당된 자원을 사용
• 해제(Release / Close)
– 할당된 자원을 운영체제에게 반환(return)

발생 원인
다른 프로세스와 공동으로 사용(공유)할 수 없는 시스템 자원을 사용할 때 주로 발생
기아 상태
Starvation
무한히 대기하고 있는 상태
교착 상태(Dead Lock)로 인한 무한한 기다림 상태
스케줄링 과정에서 더 높은 우선순위의 프로세스로 인해 계속 되는 양보
운영체제 내 교착 상태를 예방하는 과정에서 무한한 기다림이 발생

임계 구역에 따른 교착 상태
임계 변수 값의 상호 변경 상태를 대기
공유 변수를 사용할 때 발생
데이터베이스의 경우 잠금 기능에 따른 교착상태 발생

세마포어의 교착상태
서로 다른 두 세마포어 간 서로 대기상태 진입

자원 할당 그래프
자원 할당 그래프
- RAG : Resource Allocation Graph
- 프로세스가 어떤 자원을 사용 중이고 기다리는지를 표현
- 프로세스와 자원에 대하여 방향성을 갖는 화살표로 연결

다중 자원
- 여러 프로세스가 하나의 자원을 동시에 사용하는 경우
- 수용할 수 있는 프로세스 수를 사각형 안에 작은 동그라미로 표현

교착상태를 수학적으로 기술하는 방법
그래프를 수식으로 표현
G = (V,E)
V : Vertex(정점)는 Process 집합(P)과 Resource 집합(R)으로 구성
- P = {P1, P2, P3, …}
- R = {R1, R2, R3, …}
E : Edge(간선)로 구성
- 요청(Request Edge) : Pi -> Rj
- 할당(Allocation Edge) : Rj -> Pi

식사하는 철학자 문제
가정
- 식사를 위해서는 두 개의 포크를 사용해야 하나, 한 순간에는 하나의 포크 만을 쓸 수 있는 상황일 때
- 왼쪽에 있는 포크를 잡은 뒤 오른쪽에 있는 포크를 잡아야만 식사 가능

발생 조건
철학자들은 서로 포크를 공유할 수 없음
• 자원을 공유하지 못하면 교착 상태 발생
각 철학자는 다른 철학자의 포크를 빼앗을 수 없음
• 누군가 자원을 놓을 때까지 기다려야 하므로 교착 상태가 발생
각 철학자는 왼쪽 포크를 잡은 채 오른쪽 포크를 기다림
• 자원 하나를 잡은 상태에서 다른 자원을 기다리면 교착 상태가 발생
자원 할당 그래프가 원형(Circle)
• 자원을 요구하는 방향이 원을 이루면 양보를 하지 않기 때문에 교착상태가 발생

문제 해결책
- 포크 개수보다 철학자 수를 줄임
- 양쪽에 포크가 사용 가능할 때, 두 포크를 점유
- 홀수 번 위치와 짝수 번 위치 간의 포크의 잡는 순서를 달리함
교착 상태 필요조건
필요조건*
상호 배제(mutual exclusion)
• 한 프로세스가 사용하는 자원은 다른 프로세스와 공유할 수 없는 배타적인 자원
비선점(non-preemptive)
• 사용 중인 자원은 중간에 다른 프로세스가 빼앗을 수 없어야 함
점유와 대기(hold and wait)
• 프로세스가 어떤 자원을 할당 받은 상태에서 다른 자원을 기다리는 상태
원형 대기(circular wait)
• 점유와 대기를 하는 프로세스 간의 관계가 원을 이루어야 함
교착상태 분석
그래프 예*
교착상태 발생?

교착 및 기아 상태 - 예방 및 해결
교착 해결 방법
종류
예방 기법
4개의 deadlock 발생 필요 조건 중 하나를 제거
위 사항 중 하나라도 없으면, 절대 Deadlock이 발생하지 않음!!
자원의 공유를 허용
선점을 허용
모두 점유
원형 대기 조건 제거
교착 회피 방법
방법
상태:
프로세스의 수가 고정됨
- 중간에 새로운 프로세스가 생성되지 않음
자원의 종류와 수가 고정됨
프로세스가 요구하는 자원과 최대 수량을 알고 있음
프로세스는 자원을 사용 후 반납
※ 현실적이지 못함(Not Practical)
Dijkstra’s Algorithm
은행원 알고리즘
은행원 알고리즘 예 1

은행원 알고리즘 예 2
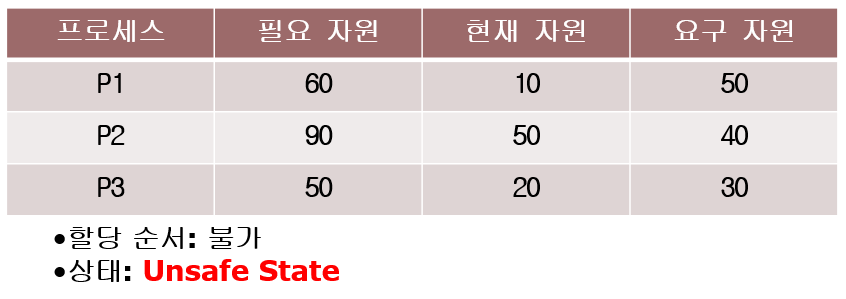
Habermann’s Algorithm
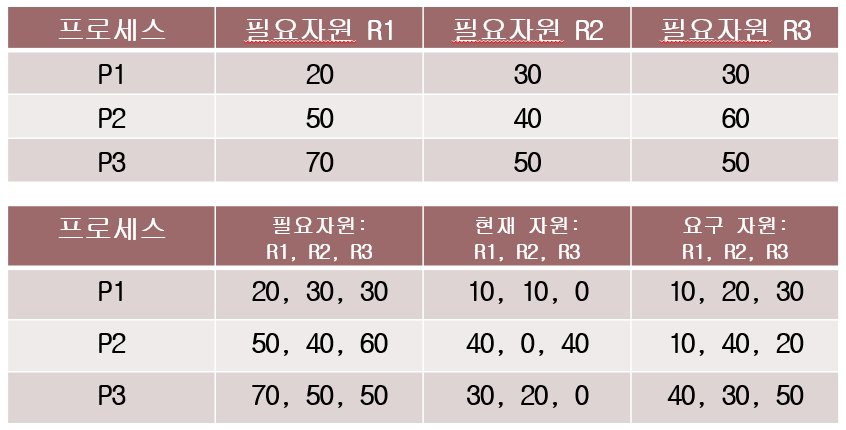
Habermann’s Algorithm
Habermann’s Algorithm 예 1

Habermann’s Algorithm 예 2
교착 회피 정리
정리
탐지 및 복구
교착 상태에 대한 탐지
교착상태에 대한 복구
복구
프로세스 종료(Process Termination)
자원을빼앗음(ResourcePreemption)
'2-1 > 운영체제' 카테고리의 다른 글
| 운영체제 9주차 정리 - 1 (0) | 2023.04.27 |
|---|---|
| 운영체제 중간고사 키워드 정리 (0) | 2023.04.19 |
| 운영체제 8주차 중간고사 공지 (0) | 2023.04.13 |
| 운영체제 7주차 정리 - 2 (0) | 2023.04.10 |
| 운영체제 7주차 정리 - 1 (0) | 2023.04.10 |


