
브래의 슬기로운 코딩 생활
빅데이터 5주차 정리 - 단일, 다중 변수 자료의 탐색 본문
자료의 특성에 따른 분류




#막대그래프
barplot(데이터셋, main='타이틀')

#원그래프
pie(데이터셋, main='타이틀')

평균과 중앙값
연속형 자료는 관측값들이 크기를 가지기 때문에 범주형 자료에 비해 다양한 분석 방법이 존재

평균, 중앙값 : 전체 데이터를 대표할 수 있는 값
- 평균 : 자료의 값들을 모두 더한후 자료의 개수로 나눈 값
- 중앙값(median) : 자료의 값들을 크기순으로 일렬로 줄 세웠을 때, 가장 중앙에 위치하는 값


사분위수
사분위수(quatile)란 주어진 자료에 있는 값들을 크기순으로 나열했을 때 이것을 4등분하는 지점에 있는 값들을 의미
자료에 있는 값들을 4등분하면 등분점이 3개 생기는데, 앞에서부터 ‘제1사분위수(Q1)’,
‘제2사분위수(Q2)’, ‘제3사분위수(Q3)’라고 부르며, 제2사분위수(Q2)는 중앙값과 동일
전체 자료를 4개로 나누었기 때문에 4개의 구간에는 각각 25%의 자료가 존재


히스토그램
hist(데이터셋, ~~~)
히스토그램(histogram)은 외관상 막대그래프와 비슷한 그래프로, 연속형 자료의 분포를 시각화할 때 사용

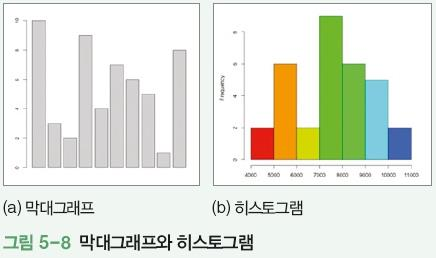
막대그래프와 히스토그램 비교
일반적으로 막대 사이에 간격 있으면 막대그래프, 간격 없이 막대들이 붙어 있으면히스토그램
막대그래프에서는 막대의 면적이 의미가 없지만 히스토그램에서는 막대의 면적도의미가 있음
상자그림
boxplot(데이터셋, main='타이틀')
상자그림(box plot)은 사분위수를 시각화하여 그래프 형태로 나타낸 것

산점도
다중변수 자료(또는 다변량 자료): 변수가 2개 이상인 자료
다중변수 자료는 2차원 형태를 나타내며, 이는 매트릭스나 데이터 프레임에 저장하여 분석

산점도(scatter plot): 2개의 변수로 구성된 자료의 분포를 알아보는 그래프
#산점도
plot(데이터셋1, 데이터셋2, main='타이틀')

#여러 변수 산점도
pairs(데이터셋, main='타이틀')

상관분석
피어슨 상관계수(Pearson’s correlation coefficient)
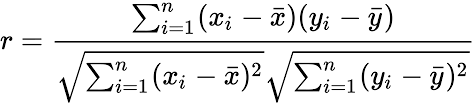
-1 ≤ r ≤ 1
- r > 0 : 양의 상관관계(x가 증가하면 y도 증가)
- r < 0 : 음의 상관관계(x가 증가하면 y는 감소)
- r이 1이나 –1에 가까울수록 x, y의 상관성이 높음

회귀식 <- lm(데이터1~데이터2,data=데이터프레임l) # 회귀식 도출
abline(회귀식) # 회귀선 그리기
cor(데이터1,테이터2) # 데이터1과 데이터2의 상관도 계산

선그래프
#선그래프
plot(데이터셋1,데이터셋2, main='타이틀’, type= "l" )



'3-1 > 빅데이터' 카테고리의 다른 글
| 빅데이터 6주차 정리 - 데이터 전처리 (0) | 2024.04.05 |
|---|---|
| 빅데이터 4주차 정리 - 조건문, 반복문, 함수 (0) | 2024.03.28 |
| 빅데이터 3주차 정리 - 데이터 다루기 (0) | 2024.03.20 |
| 빅데이터 2주차 정리 - 벡터, 매트리스, 데이터프레임 (0) | 2024.03.13 |
| 빅데이터 1주차 정리 - Rstudio 사용법, 변수와 벡 (0) | 2024.03.08 |



