
브래의 슬기로운 코딩 생활
데이터베이스 중간고사 정리 본문
데이터 베이스의 시작
파일 시스템
특징
데이터 베이스 관리 시스템 (DBMS)
특징
파일 시스템과 DBMS의 차이점

데이터베이스 용어
관계형 데이터베이스
여러 개의 테이블이 특정 관계로 이루어져 있는 구조를 가진 데이터 베이스
엔티티 (Entity)
사람, 장소, 사물, 사건 등과 같이 독립적으로 존재하면서 고유하게 식별이 가능한 실세계의 개체
엔티티 집합 (Entity Set)
동일한 속성을 가진 엔티티들의 집합. 엔티티 집합에 속한 요소들이 여러 엔티티 집합에 속할 수도 있다
스키마 (Schema)
데이터베이스에 저장되는 데이터 구조와 제약조건을 정의한 것
외부 스키마 (사용자 관점)
각 사용자가 생각하는 데이터베이스의 모습
- 하나의 데이터베이스에 여러 개의 외부 스키마 존재 가능
개념 스키마 (조직 전체 관점)
저장되는 개체, 개체관의 관계 및 제약 조건, 접근 권한, 보안 등을 정의
- 하나의 데이터베이스에 하나의 개념 스키마만 존재
내부 스키마 (저장 장치 관점)
레코드 구조, 필드 크기, 레코드 접근 경로 등 물리적 저장 구조를 정의
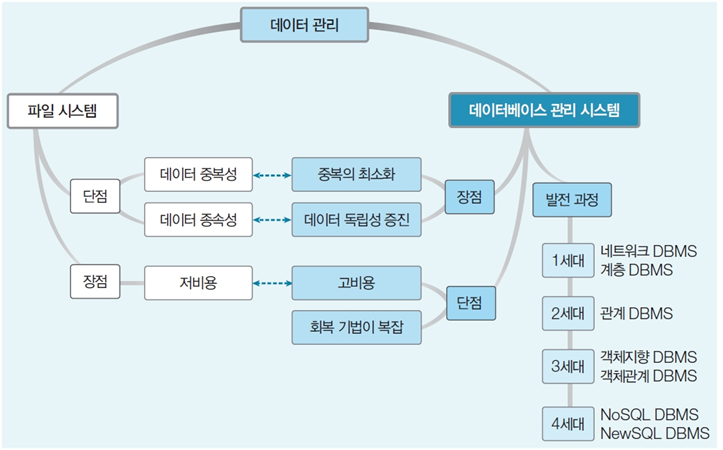
표 (TABLE) 용어
Relation (TABLE)
관계형 데이터 베이스에서 정보를 구분하여 저장하는 기본 단위
Attribute (속성)
TABLE의 열 (FIELD, COLUMN으로도 불림)
Tuple
TABLE의 행 (RECORD, ROW로도 불림)
Domain
Attribute이 가질 수 있는 값의 집합
Degree (차수)
Attribute (열)의 개수
Cardinality
Tuple (행)의 개수
CREATE DATABASE (DB이름);
SHOW DATABASES;
USE (DB 이름);
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
column3 datatype,
.
.
. );
DATATYPES
표를 만들 때 각 열의 domain을 datatype들을 이용해서 정해줘야 한다. 주로 이용하는 datatype들은 다음과 같다.

이 외에도 BIT, BINARY, BLOB, BOOL 등이 있다.
간단한 QUERY (구문)
SQL 구문은 무조건 ; 으로 끝나야 실행된다
즉, 엔터 키로 줄을 띄는 것은 문법에 상관없다

INSERT INTO
INSERT INTO table_name(column1, column2, column3, …)
VALUES (value1, value2, value3, …);
여기서 column1에 value1이 입력이 되는 것이다
입력하는 값의 길이가 열의 개수와 일치하면 column1…은 생략해도 된다
INSERT INTO table_name
VALUES (value1, value2, value3, …);
SELECT
SELECT column1, column2, …
FROM table_name
WHERE condition; (조건절 없이 사용하면 모든 값)
여기서 표에서 모든 열을 불러오고 싶으면 column1, column2, … 을 나열하지 않고
별표 ( * )로 대체하면 된다
SELECT * FROM table_name;
UPDATE
UPDATE table_name
SET column1 = value1, column2 = value2, …
WHERE condition;
조건절 없이 사용하면 모든 값을 바꾼다
DELETE
DELETE FROM table_name;
- 표에 있는 모든 열을 삭제한다
DELETE FROM table_name WHERE condition;
- 표에 있는 특정 값들만 지우고 싶다면 조건절 WHERE과 함께 사용해야한다
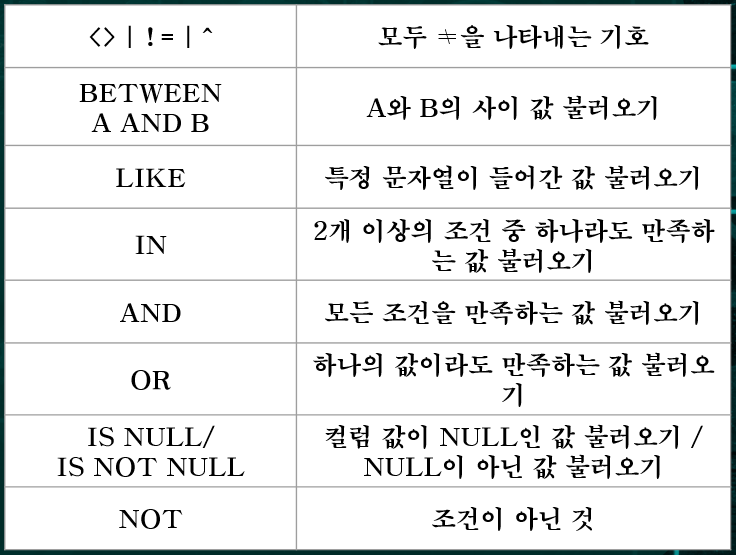
WHERE
WHERE condition;
- 조건절은 혼자 사용 못하지만 값을 추리는데 사용한다
condition에 사용되는 operator들은 연산자 =, <, >, >=, <= 과 다음들이 있다
테이블 스키마 바꾸기
column 추가
ALTER TABLE table_name
ADD column_name datatype;
column 삭제
ALTER TABLE table_name
DROP column_name;
column 이름 변경
ALTER TABLE table_name
RENAME column_name to new_name;
column 스미카 변경
ALTER TABLE table_name
MODIFY COLUMN column_name new_datatype;
데이터베이스 언어 종류
저장된 데이터를 실질적으로 처리하는데 사용하는 언어.
데이터 베이스의 생성 및 변경, 제거
SELECT UPDATE INSERT DELETE 등
데이터 베이스를 정의하는 언어.
데이터베이스 안의 값들을 변경, 수정, 입력.
CREATE DROP ALTER 등
데이터베이스에 접근하거나 객체에 권한을 주는 역할.
데이터 베이스의 접속 권한 등을 수정.
GRANT REVOKE 등
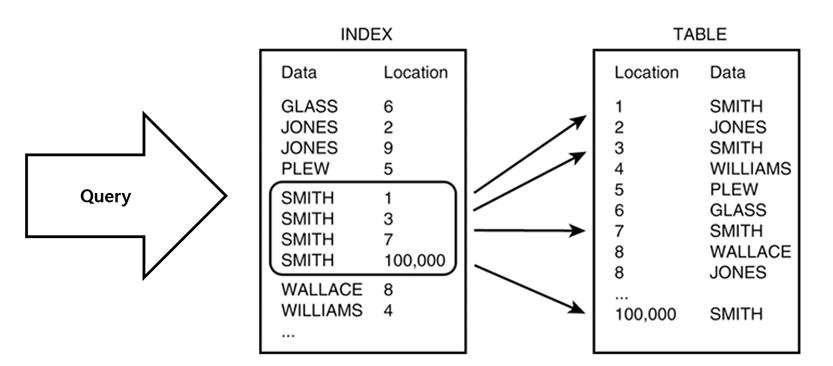
인덱스 (INDEX)
키 (KEY)
> PRIMARY KEY
> UNIQUE KEY
> INDEX
Foreign Key (외래키)
Foreign Key 설정하기
CREATE TABLE table_name(
column1 datatype;
column2 datatype;
…
FOREIGN KEY (column#) REFERENCES parent_table(key)
ALTER TABLE table_name
ADD FOREIGN KEY (column_name) REFERENCES parent_table(key)
Foreign Key 를 설정하는 이유
참조무결성
1) On Delete:
Cascade : 부모 데이터 삭제 시 자식 데이터도 삭제
Set null : 부모 데이터 삭제 시 자식 테이블의 참조 컬럼을 Null로 업데이트
Set default : 부모 데이터 삭제 시 자식 테이블의 참조 컬럼을 Default 값으로 업데이트
Restrict : 자식 테이블이 참조하고 있을 경우, 데이터 삭제 불가
No Action : Restrict와 동일, 옵션을 지정하지 않았을 경우 자동으로 선택된다.
2) On Update:
Cascade : 부모 데이터 업데이트 시 자식 데이터도 업데이트
Set null : 부모 데이터 업데이트 시 자식 테이블의 참조 컬럼을 Null로 업데이트
Set default : 부모 데이터 업데이트 시 자식 테이블의 참조 컬럼을 Default 값으로 업데이트
Restrict : 자식 테이블이 참조하고 있을 경우, 업데이트 불가
No Action : Restrict와 동일, 옵션을 지정하지 않았을 경우 자동으로 선택된다.
Primary Key (기본키)
Primary Key (기본키) 설정하기
CREATE TABLE table_name(
column1 datatype NOT NULL PRIMARY KEY,
column2 datatype,
…
);
ALTER TABLE table_name
ADD PRIMARY KEY (column_name);
이 경우에는 primary key로 설정하는 column이 NOT NULL이어야 한다.
Unique Key (유니크키)

Unique Key (유니크키) 설정하기
CREATE TABLE table_name(
column1 datatype UNIQUE,
column2 datatype UNIQUE,
column3 datatype,
…
);
혹은
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
column3 datatype,
…,
UNIQUE INDEX index1_name (column1),
UNIQUE INDEX index2_name (column2)
);
ALTER TABLE table_name
ADD UNIQUE INDEX index_name (column_name);
혹은
ALTER TABLE table_name
ADD UNIQUE (column_name);
Index Key (인덱스키)
Index Key (인덱스키) 설정하기
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
column3 datatype,
…,
INDEX index1_name (column1),
INDEX index2_name (column2)
);
ALTER TABLE table_name
ADD INDEX index_name (column_name);
AUTO_INCREMENT
AUTO_INCREMENT는 각 칼럼의 기본값으로 설정해 줄 수 있는 옵션 중 하나이다.
- 주로 고유 식별자 번호를 자동으로 발급하는데 사용된다.
- 레코드의 값이 중복되지 않고 1씩 자동 증가하게 된다
※ INSERT INTO로 레코드 추가시 AUTO_INCREMENT에 해당하는 컬럼에 NULL을 넣거나
입자 목록에서 생략하면자동으로 값이 채워진다.
2개 이상의 칼럼을 Key로 묶기
Key(Primary, Unique, Index Key)들은 여러 개의 속성들을 묶어서 키로 만들 수도 있다.
•Primary Key
CREATE TABLE table_name(
column1 datatype NOT NULL,
column2 datatype NOT NULL,
…
CONSTRAINT key_name PRIMARY KEY (column1, column2)
);
ALTER TABLE table_name
ADD CONSTRAINT key_name PRIMARY KEY (column1, column2);
•Foreign Key
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
…
CONSTRAINT key_name FOREIGN KEY (column1, column2)
REFERENCES parent_table(key1, key2)
);
ALTER TABLE table_name
ADD CONSTRAINT key_name FOREIGN KEY (column1, column2)
REFERENCES parent_table(key1, key2);
•Unique Key
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
…
CONSTRAINT key_name UNIQUE (column1, column2)
);
ALTER TABLE table_name
ADD CONSTRAINT key_name UNIQUE (column1, column2);
•Index Key
CREATE INDEX index_name
ON table_name (column1, column2, …);
NOT NULL 설정하기
칼럼 값에 NULL이 들어갈 수 없게 NOT NULL을 컬럼 옵션으로 추가할 수 있다.
key가 아닌 속성들도 NOT NULL로 설정할 수 있다.
방법 1) 테이블을 만들 때 선언
CREATE TABLE table_name(
column1 datatype NOT NULL,
column2 datatype NOT NULL,
…
);
방법 2) 이미 만들어진 테이블 변경하기
ALTER TABLE table_name
MODIFY column_name datatype NOT NULL;
무결성 제약조건 이란?
•무결성 제약조건 이란 데이터베이스의 정확성, 일관성을 보장하기 위해
저장, 삭제, 수정 등을 제약하기 위한 조건을 뜻한다
개념적 Key의 종류
슈퍼키
튜플을 유일하게 식별할 수 있는 하나의 속성 혹은 속성의 집합
튜플을 유일하게 식별할 수 있는 값이면 모두 슈퍼키가 될 수 있음
후보키
튜플을 유일하게 식별할 수 있는 속성의 최소 집합
2개 이상의 속성으로 이루어진 키를 복합키(composite key)라고 함
기본키
- 여러 후보키 중 하나를 선정하여 대표로 삼는 키
릴레이션 이름(속성1, 속성2, …. 속성N)
대리키
기본키가 보안을 요하거나, 여러 개의 속성으로 구성되어 복잡하거나, 마땅한 기본키가 없을 때는
일련번호 같은 가상의 속성을 만들어 기본키로 삼는 경우가 있음
이러한 키를 대리키(surrogate key) 혹은 인조키(artificial key)라고 함
대체키
기본키로 선정되지 않은 후보키
외래키
다른 릴레이션의 기본키를 참조하는 속성을 말함
외래키의 특징
- 외래키가 기본키의 일부가 될 수 있음
개념적 키 요약

인덱스 더 알아보기
인덱스는 B-Tree 형태로 만들어진다
B-Tree : Balanced Tree, 균형트리. DBMS는 빠른 값 검색을 위해 Key를 B-Tree로 정렬해 둔다.
클러스터 방식: B-Tree의 말단에 바로 데이터를 정렬해 두는 방식
논클러스터 방식: B-Tree의 말단에 바로 데이터의 주소를 저장해 두는 방식

ORDER BY
ORDER BY는 조회한 레코드 목록을 정렬할 때 사용한다.
ASC 키워드로 오름차순 정렬, DESC 키워드로 내림차순 정렬이 된다.
(생략하면 오름차순 정렬 됨)
SELECT column1
FROM table_name
ORDER BY column1 ASC | DESC;
정렬 기준을 여러 개의 속성으로 할 때는 ‘ , ’를 이용해 속성 이름을 나열한다.
(column1 값이 같으면 column2를 기준으로 정렬)
SELECT column1, column2, …
FROM table_name
ORDER BY column1 ASC | DESC, column2 ASC | DESC
집계 함수 (AGGREGATE FUNCTION)
집계 함수는 여러 행으로부터 하나의 계산 값을 반환하는 함수이다.
SELECT 문에만 사용 가능하다.
선택한 칼럼의 NULL을 제외한 행의 개수를 센다.
COUNT(*)로 작성하면 테이블에 존재하는 행의 개수를 반환한다.
선택한 칼럼의 평균을 구한다.
숫자인 값에 대해서만 연산이 가능하다. NULL 값은 무시하고 계산한다.
선택한 칼럼의 합을 구한다.
평균과 마찬가지로 숫자인 값에 대해서면 연산이 가능하다.
MIN(column1) | MAX(column1)
선택한 칼럼의 최솟값과 최댓값을 구한다.
AVG와 SUM과 다르게 숫자가 아닌 값에도 연산이 가능하다.
GROUP BY / HAVING
column1을 기준으로 그룹을 만든 후 그 안에서 column2를 기준으로 하는 그룹을 만든다.
WHERE절과는 다르게 집계 함수와 함께 사용 가능하다.
※ SELECT문과 사용되는 구문들의 순서 ※
SELECT … FROM … WHERE … GROUP BY … HAVING … ORDER BY
GROUP BY와 HAVING절의 문법과 주의사항

JOIN
두 개 이상의 테이블을 서로 연결하여 데이터를 검색할 때 사용하는 방법
두 개의 테이블을 마치 하나의 테이블인 것처럼 보여준다
두 테이블의 조인을 위해 키(KEY)와 외래키(FOREIGN KEY) 관계를 설정해 두면 속도 향상의 이점이 있다
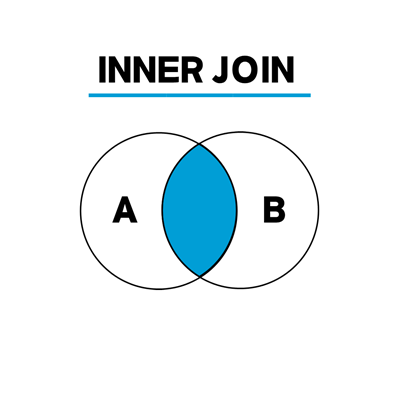
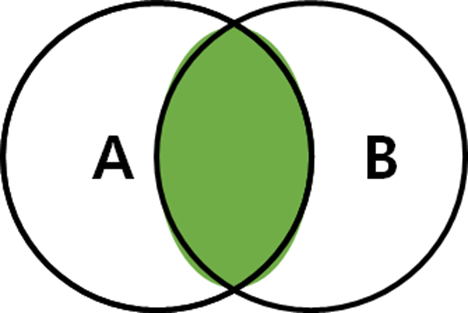
INNER JOIN (내부 조인)
두 테이블에 지정한 컬럼의 데이터가 있는 경우만 조회
SELECT column1, column2, …
FROM table_A
INNER JOIN table_B
ON table_A.column = table_B.column;
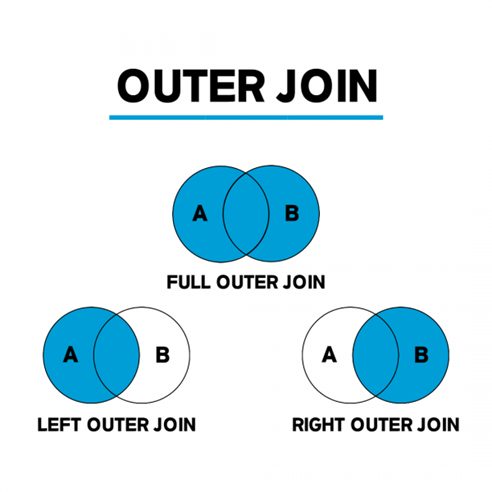
OUTER JOIN (외부 조인)
두 테이블 중 하나의 테이블에만 지정한 컬럼에 값이 있어도 조회
SELECT column1, column2, …
FROM table_A – (LEFT 테이블)
<LEFT | RIGHT | FULL> OUTER JOIN table_B – (RIGHT 테이블)
ON table_A.column = table_B.column;
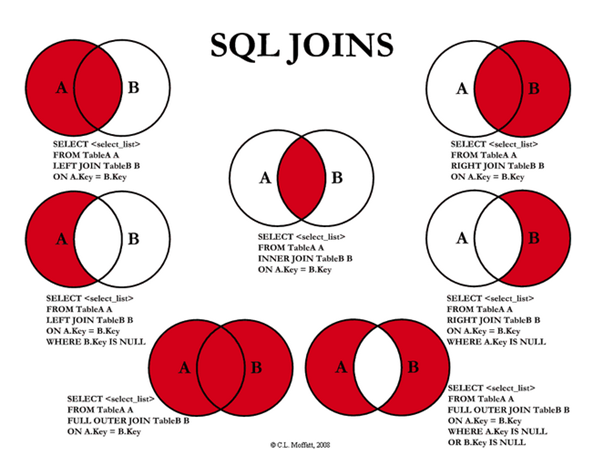
JOIN문 문법

JOIN 보강

INNER JOIN
SELECT *
FROM A
INNER JOIN B
ON A.key = B.key;
LEFT OUTER JOIN
SELECT *
FROM A
LEFT OUTER JOIN B
ON A.key = B.key;

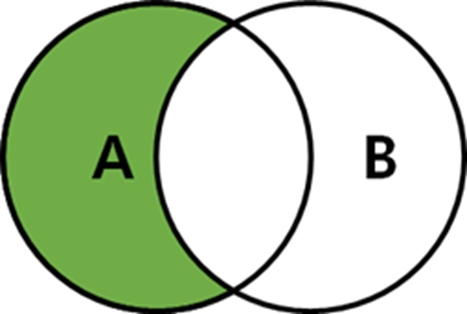
LEFT OUTER JOIN (순수 A만 구할때)
SELECT *
FROM A
LEFT OUTER JOIN B
ON A.key = B.key
WHERE B.key IS NULL;
RIGHT OUTER JOIN
SELECT *
FROM A
RIGHT OUTER JOIN B
ON A.key = B.key;

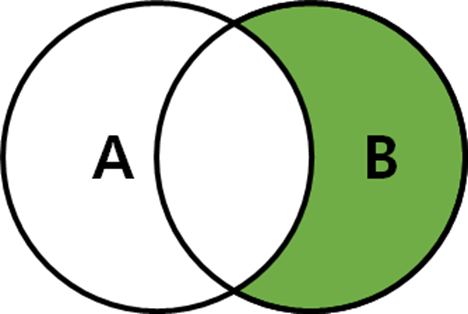
RIGHT OUTER JOIN (순수 B만 구할때)
SELECT *
FROM A
RIGHT OUTER JOIN B
ON A.key = B.key
WHERE A.key IS NULL;
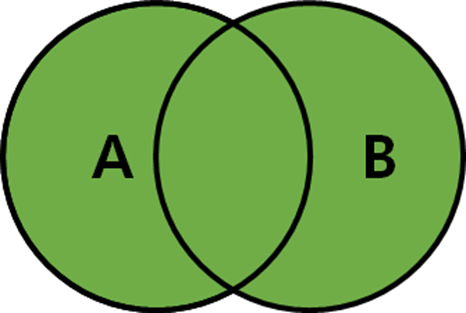
FULL OUTER JOIN
SELECT * FROM A LEFT OUTER JOIN B
ON A.key = B.key
UNION
SELECT * FROM A RIGHT OUTER JOIN B
ON A.key = B.key;
FULL OUTER JOIN (교집합 제외)
SELECT * FROM A LEFT OUTER JOIN B
ON A.key = B.key
WHERE B.key IS NULL
UNION
SELECT * FROM A RIGHT OUTER JOIN B
ON A.key = B.key
WHERE A.key IS NULL;

내장 함수


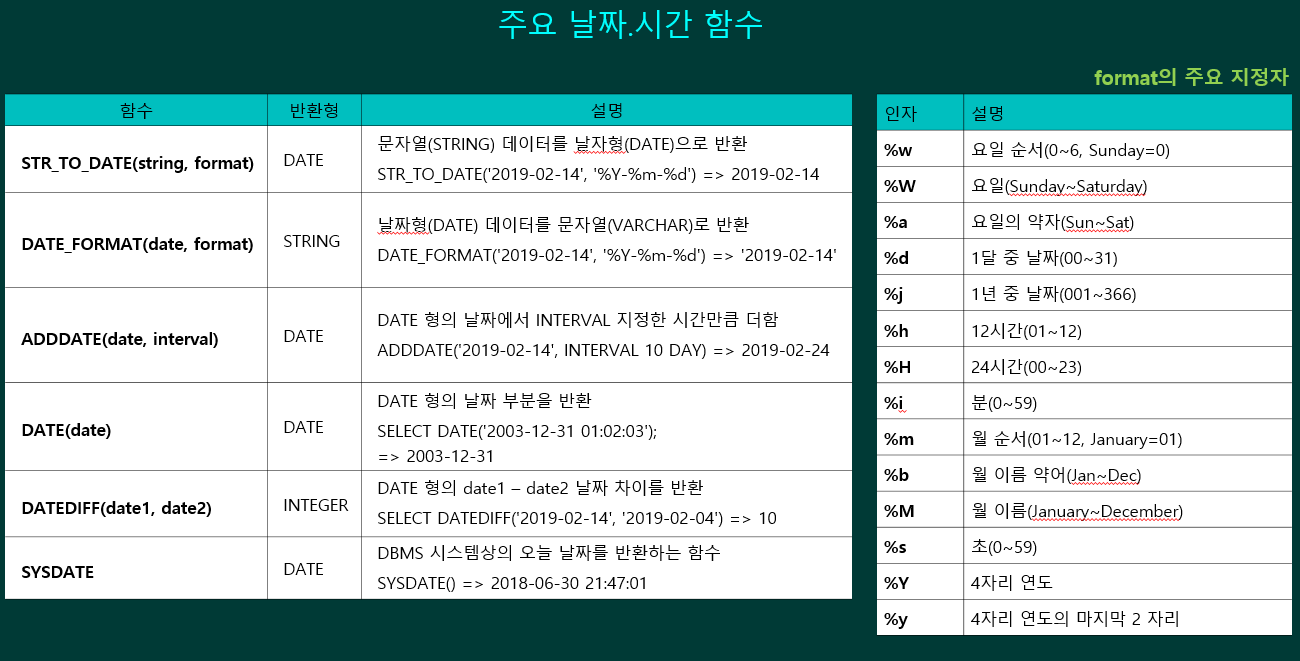
주요 NULL 함수
NULL 값을 확인하는 방법 – IS NULL, IS NOT NULL
NULL 값을 찾을 때는 '='연산자가 아닌 ‘IS NULL'을 사용,
NULL이 아닌 값을 찾을 때는 '<>’ 연산자가 아닌 'IS NOT NULL'을 사용함
IFNULL(속성, 값) : 속성 값이 NULL이면 값으로 대치하여 출력
부속 질의
•주질의(main query, 외부질의)와 부속질의(sub query, 내부질의)로 구성됨
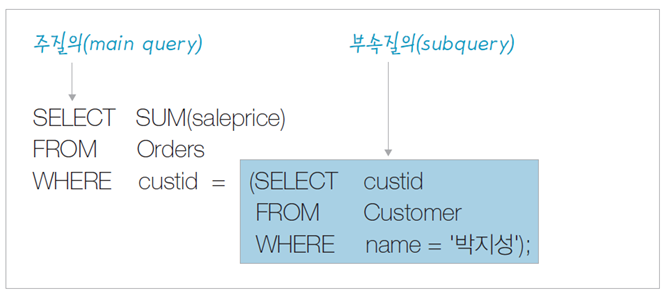
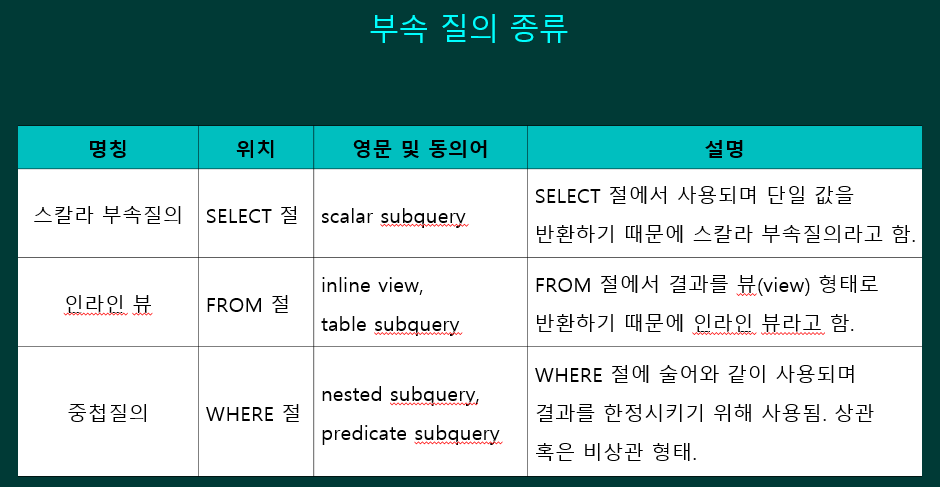
스칼라 부속 질의 (Scalar Subquery) – SELECT 부속 질의
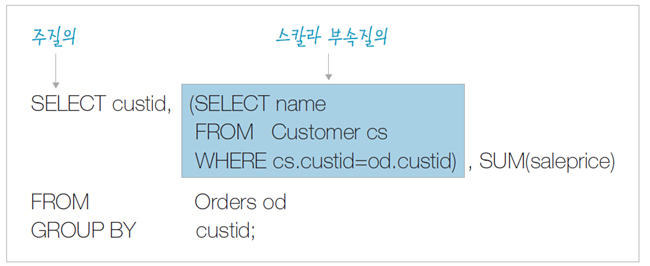
인라인 뷰 (Inline View) – FROM 부속 질의
중첩 질의 (Nested Subquery) – WHERE 부속 질의

IN, NOT IN
- NOT IN은 이와 반대로 값이 존재하지 않으면 참이 됨
ALL, SOME (ANY)

EXISTS, NOT EXISTS

'2-1 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스 10주차 정리 (0) | 2023.05.08 |
|---|---|
| 데이터베이스 7주차 정리 (0) | 2023.04.17 |
| 데이터베이스 8주차 중간고사 공지 (0) | 2023.04.13 |
| 데이터베이스 6주차 정리 (0) | 2023.04.10 |
| 데이터베이스 5주차 과제 (0) | 2023.04.04 |

