
브래의 슬기로운 코딩 생활
데이터베이스 기말고사 정리 본문
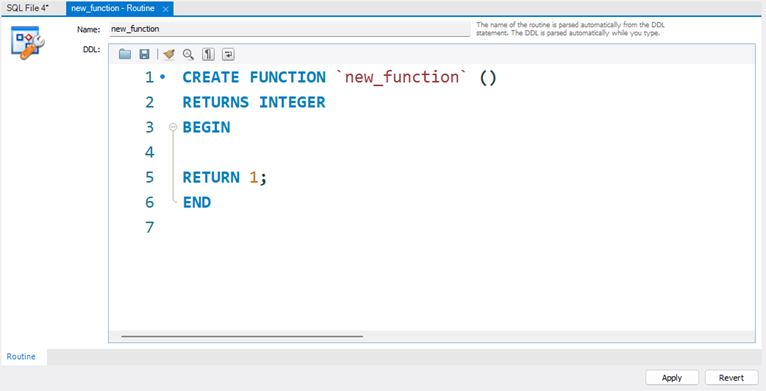
사용자 정의 함수 - User-Defined Function
사용자 정의함수 (User-Defined Function)
SELECT customer_id, order_id, sale_price, fnc_interest(sale_price) 'interest'
FROM orders;

사용자 정의함수 문법
CREATE FUNCTION function_name
(parameter1 datatype, parameter2 datatype, …)
RETURNS return_type
BEGIN
// function_body
RETURN return_value
END;
VIEW (뷰)
VIEW (뷰)
뷰의 장점*
→ 복잡한 질의를 간단히 작성
→ 개인정보(주민번호)나 급여, 건강 같은 민감한 정보를 제외한 테이블을 만들어 사용
→ 원본 테이블의 구조가 변해도 응용에 영향을 주지 않도록 하는 논리적 독립성 제공
뷰의 특징*
VIEW 생성
CREATE VIEW view_name (column_names) AS
SELECT column1, column2, …
FROM table_name
WHERE condition;
VIEW 수정
CREATE OR REPLACE VIEW view_name (column_names) AS
SELECT …
FROM table_name
WHERE condition;
VIEW 삭제
DROP VIEW view_name;
저장 프로그램 - 프로시저
저장 프로그램 (Stored Program)
Procedure (프로시저)
삽입 작업을 하는 프로시저
프로시저로 데이터 삽입 작업을 하면 좀 더 복잡한 조건의 삽입 작업을 인자 값만 바꾸어 수행할 수도 있고,
저장해 두었다가 필요할 때마다 호출하여 사용할 수도 있음
products 테이블에 한 개의 레코드를 삽입하는 프로시저를 만들어라

새로 만든 프로시저를 이용해 (가디건, 톰브라운, 100000)을 product 테이블에 추가해라
※ 프로시저는 CALL 명령어를 이용한다.
제어문을 사용하는 프로시저
저장 프로그램의 제어문은 어떤 조건에서 어떤 코드가 실행되어야 하는지를 제어하기 위한 문법으로,
절차적 언어의 구성요소를 포함함

데이터를 입력하기 전, 동일한 상품이 있는지 확인하고 삽입하는 프로시저를 만들어라

결과를 변환하는 프로시저
함수와 같이 계산된 결과를 반환해주는 프로시저이다.
저장 프로시저 매개변수에는 3가지 모드가 있다*
초기값은 프로시저 내에서 NULL값이며 프로시저가 반환될 때 새로운 값이 호출자에게 리턴된다 (FUNCTION의 RETURNS ***와 비슷하다)
products 테이블에 저장된 상품들의 평균 가격을 반환하는 프로시저를 작성해라

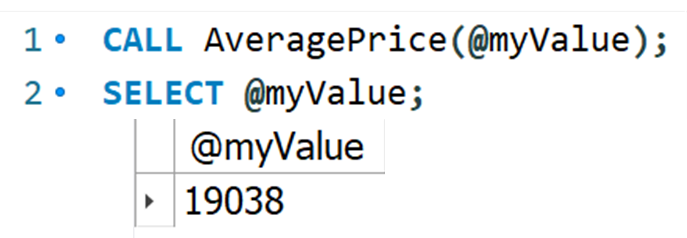
사용자가 설정하는 변수 (User Defined Variable)은 @value_name으로 설정한다.
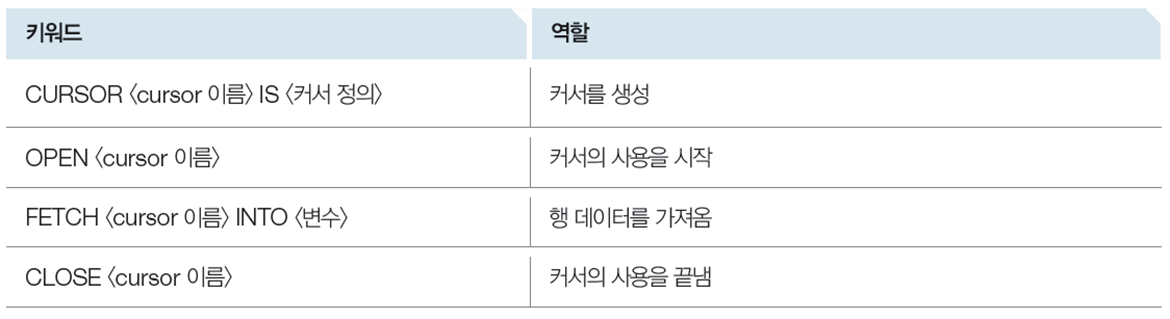
커서를 사용하는 프로시저
- 커서(cursor)는 실행 결과 테이블을 한 번에 한 행씩 처리하기 위하여 테이블의 행을 순서대로 가리키는 데 사용함
- 커서에 사용되는 키워드*



트리거
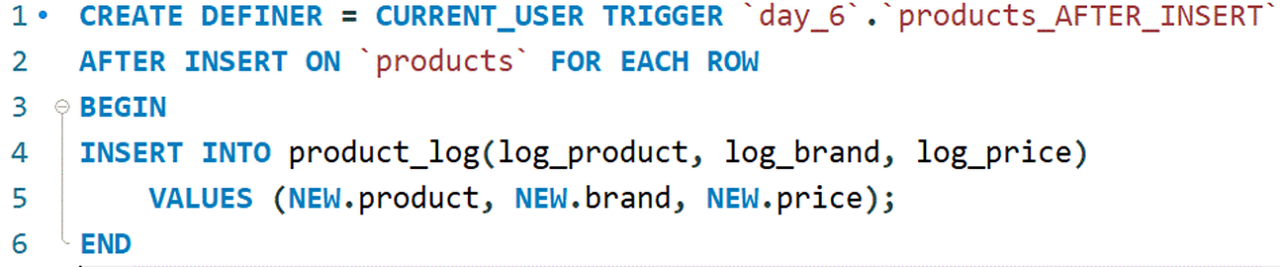
트리거
트리거(trigger) : 데이터의 변경(INSERT, DELETE, UPDATE) 문이 실행될 때 자동으로 따라서 실행되는 프로시저
부수적으로 필요한 작업인 데이터 기본값 제공, 데이터 제약 준수, SQL 뷰의 수정 등을 실행
※Workbench에서 트리거 작동을 위해 다음 문장 실행
SET global log_bin_trust_function_creators = ON;
새로운 상품을 삽입한 후 자동으로 product_log 테이블에 삽입한 내용을 기록하는 트리거 생성



트랜잭션
트랜잭션의 개념
트랜잭션(transaction): DBMS에서 데이터를 다루는 논리적인 작업의 단위
트랜잭션은 전체가 수행되거나 또는 전혀 수행되지 않아야 함(all or nothing).
트랜잭션의 성질 *
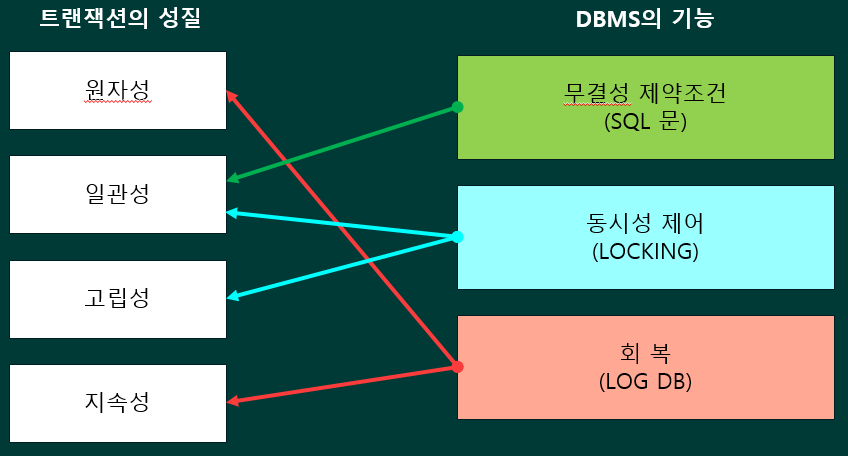
동시성 제어
동시성 제어
동시성 제어(concurrency control) : 트랜잭션이 동시에 수행될 때, 일관성을 해치지 않도록 트랜잭션의 데이터 접근을 제어하는 DBMS의 기능
같은 데이터를 접근하는 두 트랜잭션의 작업(읽기, 쓰기)에 따라 발생하는 상황

위 [상황 3]을 '갱신손실 문제 (LOST UPDATE)'라고 하며
두 개의 트랜잭션이 한 개의 데이터를 동시에 갱신(update)할 때 발생하며,
데이터베이스에서 절대 발생하면 안 되는 현상
락
- 갱신손실 문제를 해결하려면 상대방 트랜잭션이 데이터를 사용하는지 여부를 알 수 있는 규칙이 필요함
락 유형
오손 읽기 (Dirty Read)*
- 읽기 작업을 하는 트랜잭션 1이 쓰기 작업을 하는 트랜잭션 2가 작업한 중간 데이터를 읽기 때문에 생기는 문제
- 작업 중인 트랜잭션 2가 어떤 이유에서 작업을 철회(ROLLBACK)할 경우
트랜잭션 1은 무효가 된 데이터를 읽게 되고 잘못된 결과를 도출하는 현상
반복불가능 읽기 (Non-Repeatable Read)*
- 트랜잭션 1이 데이터를 읽고 트랜잭션 2가 데이터를 쓰고(갱신, UPDATE)
트랜잭션 1이 다시 한 번 데이터를 읽을 때 생기는 문제
유령데이터 읽기 (Phantom Read)*
- 트랜잭션 1이 읽기 작업을 다시 한 번 반복할 경우 이전에 없던 데이터(유령 데이터)가 나타나는 현상
회복
회복
데이터베이스에 장애가 발생했을 때 데이터베이스를 일관성 있는 상태로 되돌리는 DBMS의 기능
트랜잭션과 회복
- 트랜잭션은 변경 내용을 한순간에 모두 기록하지 않는다.
로그 파일
- 트랜잭션이 수행 중이거나 수행이 종료된 후 발생하는 데이터베이스 손실을 방지하기 위해
트랜잭션의 데이터베이스 기록을 추적하는 로그 파일(log file)을 사용함
<트랜잭션번호, 로그의 타입, 데이터 항목 이름, 수정 전 값, 수정 후 값>
로그 파일을 이용한 회복*
데이터의 변경 기록을 저장해 둔 로그 파일을 이용하면 시스템 장애도 복구할 수 있음
이상현상
이상현상의 개념
삭제이상(Deletion Anomly)
투플 삭제 시 같이 저장된 다른 정보까지 연쇄적으로 삭제되는 현상
= 연쇄삭제(Triggered Deletion) 문제 발생
삽입이상(Insertion Anomly)
투플 삽입 시 특정 속성에 해당하는 값이 없어 NULL 값을 입력해야 하는 현상
= NULL 값 문제 발생
수정이상(Update Anomly)
투플 수정 시 중복된 데이터의 일부만 수정되어 데이터의 불일치 문제가 일어나는 현상
= 불일치(Inconsistency) 문제 발생
함수 종속성
함수 종속성 개념
어떤 속성 A의 값을 알면 다른 속성 B의 값이 유일하게 정해지는 의존 관계를
속성 B는 속성 A에 종속한다 (Dependent) 혹은 속성 A는 속성 B를 결정한다(Determine) 라고 함
A → B 로 표기하며, A를 B의 결정자라고 함
함수 종속성(FD, Functional Dependency)
릴레이션 R과 R에 속하는 속성의 집합 X, Y가 있을 때, X 각각의 값이 Y의 값 한 개와 대응이 될 때
‘X는 Y를 함수적으로 결정한다’라고 하고 X→Y로 표기함.
이때 X를 결정자(Determinant)라고 하고, Y를 종속 속성 (Dependent Attribute)이라고 함.
함수 종속성은 보통 릴레이션 설계 때 속성의 의미로부터 정해짐.
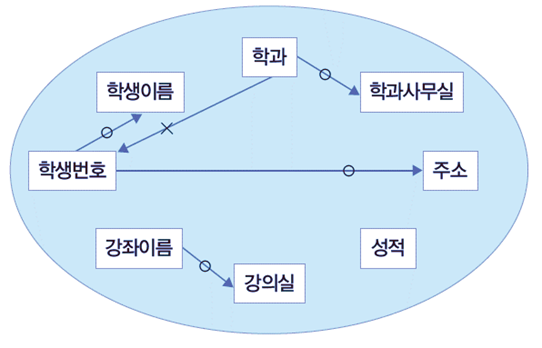
함수 종속성 규칙(Functional Dependency Rule)
X, Y, Z가 릴레이션 R에 포함된 속성의 집합이라고 할 때, 함수 종속성에 관한 다음과 같은 규칙이 성립
부분집합(Subset) 규칙 : if Y ⊆ X, then X → Y
증가(Augmentation) 규칙 : If X → Y, then XZ → YZ
이행(Transitivity) 규칙 : If X → Y and Y → Z, then X → Z
위 세 가지 규칙으로부터 부가적으로 다음의 규칙을 얻을 수 있음
결합(Union) 규칙 : If X → Y and X → Z, then X → YZ
분해(Decomposition) 규칙 : If X → YZ, then X → Y and X → Z
유사이행(Pseudotransitivity) 규칙 : If X → Y and WY → Z, then WX → Z

이상현상은 한 개의 릴레이션에 두 개 이상의 정보가 포함되어 있을 때 나타남
= 기본키가 아니면서 결정자인 속성이 있을 때 발생함*
정규화
정규화 (Normalization)
- 이상현상이 발생하는 릴레이션을 분해하여 이상현상을 없애는 과정
- 릴레이션은 정규형 개념으로 구분하며, 정규형이 높을수록 이상현상은 줄어듦
제 1정규형*
릴레이션 R의 모든 속성 값이 원자값을 가지면 제 1정규형이라고 함
제 2정규형*
- 릴레이션 R이 제 1정규형이고 기본키가 아닌 속성이 기본키에 완전 함수 종속일 때 제 2정규형이라고 함.
완전 함수 종속(Full Functional Dependency) :
A와 B가 릴레이션 R의 속성이고 A → B 종속성이 성립할 때, B가 A의 속성 전체에 함수 종속하고
부분 집합 속성에 함수 종속하지 않을 경우
불완전 함수 종속(Partial Functional Dependency) :
A → B 종속성에서 A의 속성 일부를 제거해도 종속성이 여전히 성립하는 경우
제 3정규형*
릴레이션 R이 제 2정규형이고 기본키가 아닌 속성이 기본키에
비이행적(Non-transitive)으로 종속할 때(직접 종속) 제 3정규형이라고 함
이행적 종속이란
A → B, B → C가 성립할 때 A → C가 성립되는 함수 종속성
BCNF 정규형*
- 릴레이션 R에서 함수 종속성 X → Y가 성립할 때 모든 결정자 X가 후보키이면 BCNF 정규형이라고 함
정규화 정리
대부분의 릴레이션은 BCNF까지 정규화하면 실제적인 이상현상이 없어지기 때문에 보통 BCNF까지 정규화를 진행함.

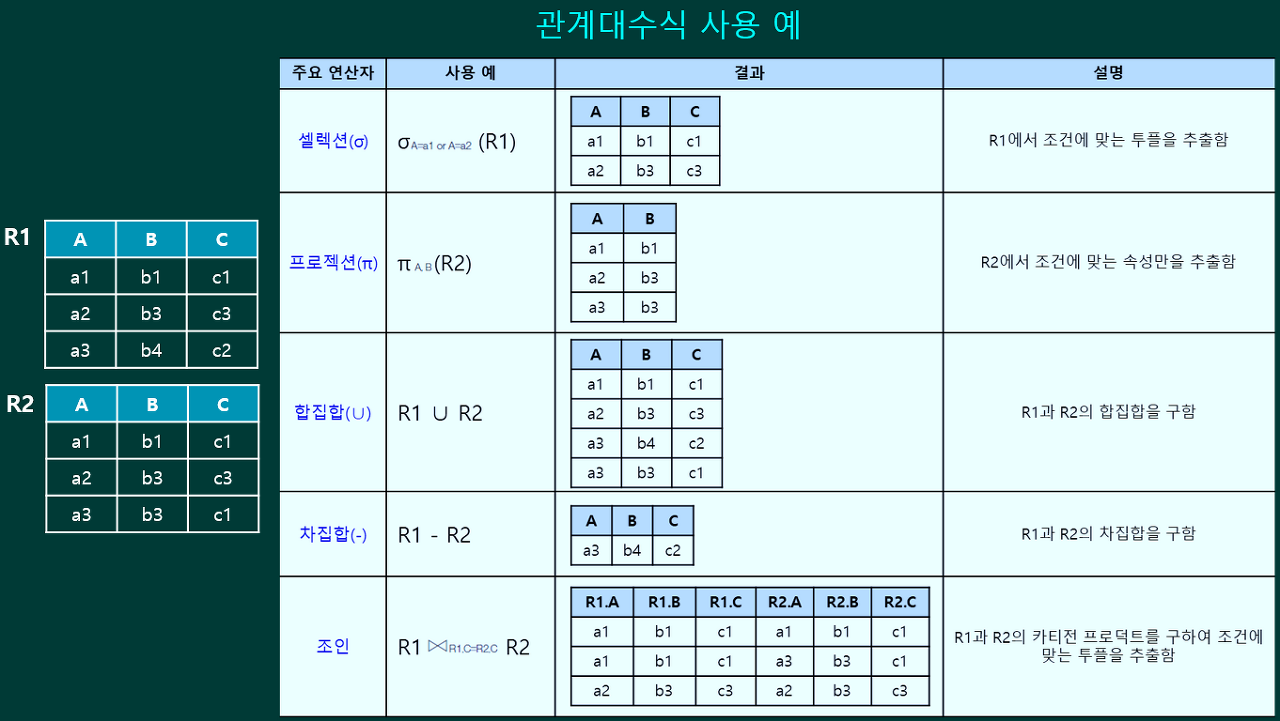
관계대수
관계대수(Relational Algebra)
릴레이션에서 원하는 결과를 얻기 위해 수학의 대수와 같은 연산을 이용하여 질의하는 방법을 기술하는 언어
관계대수와 관계해석
관계대수 : 어떤 데이터를 어떻게 찾는지에 대한 처리 절차를 명시하는 절차적인 언어이며, DBMS 내부의 처리 언어로 사용됨
관계해석 : 어떤 데이터를 찾는지만 명시하는 선언적인 언어로 관계대수와 함께 관계 DBMS의 표준 언어인 SQL의 이론적인 기반을 제공함
= 관계대수와 관계해석은 모두 관계 데이터 모델의 중요한 언어이며 실제 동일한 표현 능력을 가지고 있음.
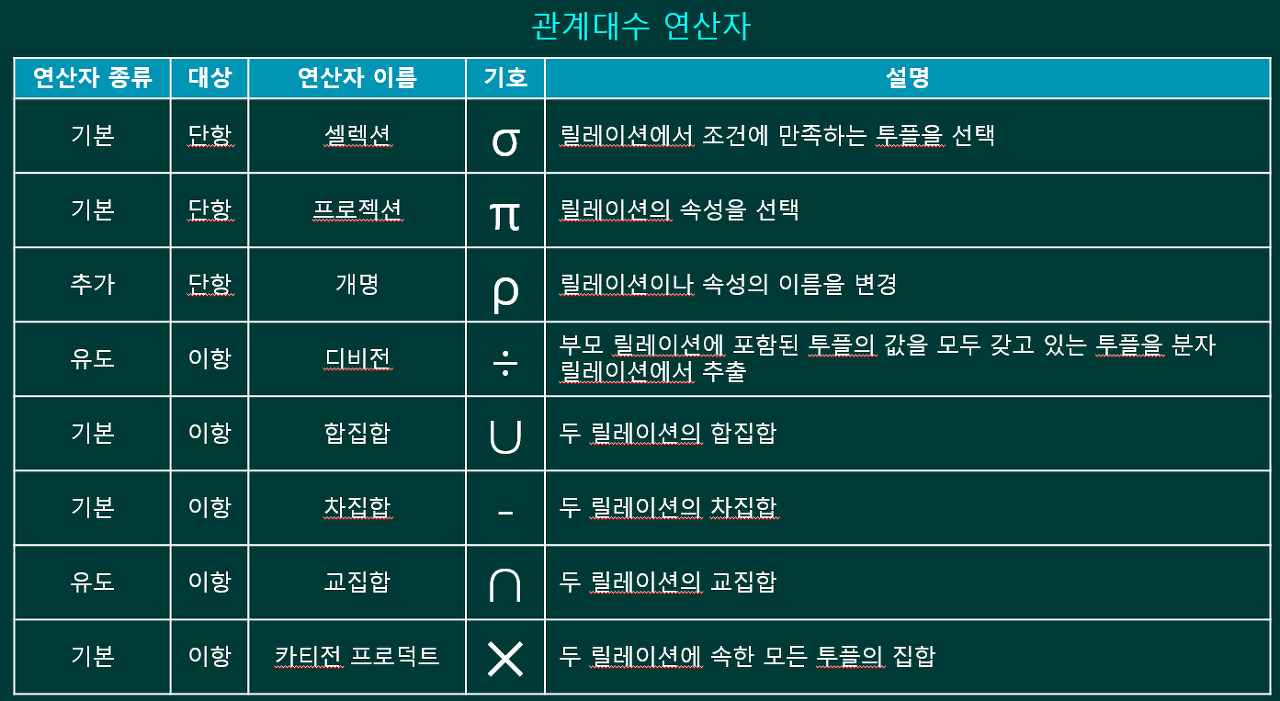
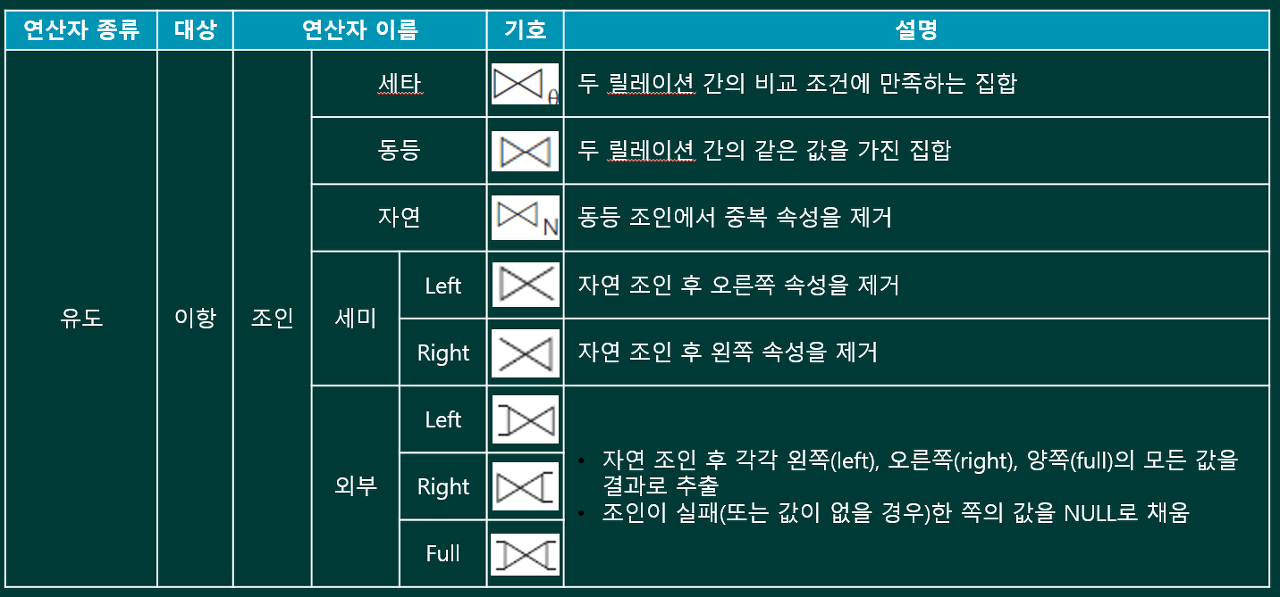
관계대수식
관계대수는 릴레이션 간 연산을 통해 결과 릴레이션을 찾는 절차를 기술한 언어로,
이 연산을 수행하기 위한 식을 관계대수식(Relational Algebra Expression)이라고 함.
관계대수식은 대상이 되는 릴레이션과 연산자로 구성되며, 결과는 릴레이션으로 반환됨. 반환된 릴레이션은 릴레이션의 모든 특징을 따름
단항 연산자 : 연산자<조건> 릴레이션
이항 연산자 : 릴레이션1 연산자<조건> 릴레이션2
데이터베이스 관리 기본 명령어
(root 계정으로) 시스템에 있는 데이터베이스 현황을 살펴보시오.
#DB에 있는 데이터베이스가 어떤 것이 있는지 보여준다.
기본적으로 mysql, sys 등 관리용 데이터베이스를 확인할 수 있다.
- SHOW DATABASES;
#데이터베이스 mysql을 사용하는 명령을 내린다.
- USE mysql;
#데이터베이스 mysql에 있는 테이블들을 보여준다.
- SHOW TABLES;
#사용자 정보를 저장하는 User 테이블의 구조를 살펴본다.
- DESC User;
#사용자 계정 테이블 user의 내용을 확인하고 사용자 계정을 살펴본다.
- SELECT * FROM User;
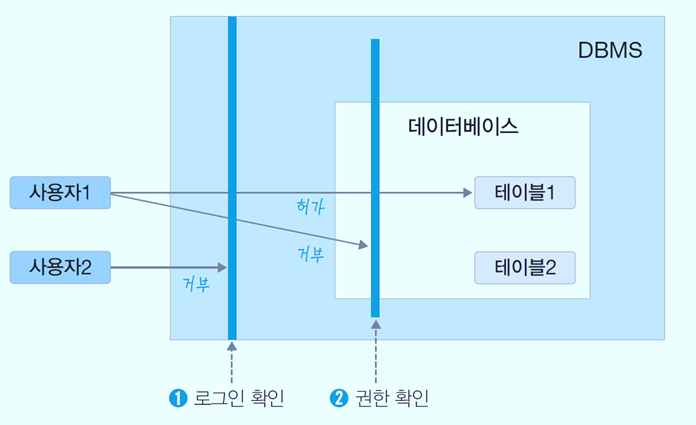
보안과 권한
보안과 권한
DBMS는
① 로그인 단계에서 DBMS 접근을 제한하는 로그인 사용자 관리
② 로그인한 사용자별로 특정 데이터로의 접근을 제한하는 권한 관리의 기능 제공
로그인 사용자 관리*
로그인 사용자 생성
- CREATE USER [사용자 이름] IDENTIFIED BY [비밀번호];
비밀번호는 IDENTIFIED BY 다음에 있는 ‘madang’이다.
CREATE USER madang@localhost IDENTIFIED BY 'madang';
외부에서 접속 가능한 madang 사용자는 다음과 같이 생성한다.
CREATE USER madang@'%' IDENTIFIED BY 'madang';
특정 사이트 ‘happy.md.kr’ 사이트에서 접속 가능한 madang 사용자 계정은 다음과 같이 생성한다.
CREATE USER madang@'%.happy.md.kr' IDENTIFIED BY 'madang';
권한 관리
권한 관리
소유한 개체에 대한 사용 권한을 관리하기 위한 명령을 DCL(Data Control Language)이라고 함
대표적 DCL 문 : 권한 허가 GRANT 문, 권한 취소 REVOKE 문
권한 허가 - GRANT
GRANT 권한 [(column_list)]
[ON 객체] TO {사용자 | ROLE}
[WITH GRANT OPTION]
- 권한 : 허가할 권한
- column_list : 사용 권한을 부여할 테이블의 열 이름들 (꼭 괄호 안에 표시해야 한다)
- 객체 : 사용 권한을 부여할 객체 지정 (테이블이나 뷰이름이 올 수 있다)
- 사용자 : 권한을 부여할 사용자를 지정
- ROLE : 권한 묶음
- WITH GRANT OPTION : 허가받은 권한을 다른 사용자에게 다시 부여할 수 있다. 없으면 재부여는 허가하지 않는다.
권한 취소 - REVOKE
REVOKE 권한 [column_list]
[ON 객체] FROM {사용자 | ROLE}
[CASCADE]
CASCADE는 사용자가 다른 사용자에게 부여한 권한까지 연쇄적으로 취소하라는 의미로,
사전에 주의 깊게 확인하고 사용해야 함
스토리지 엔진
스토리지 엔진
스토리지 엔진(Storage Engine) 혹은 데이터베이스 엔진(Database Engine)은
DBMS이 필요로 하는 물리적인 데이터를 가져오는 장치이다.
- 스토리지 엔진의 특성에 따라 데이터 접근이 얼마나 빠른지, 얼마나 안정적인지,
트랜잭션 등의 기능을 제공하는지 등의 차이점이 발생한다
흔히 쓰는 스토리지 엔진 종류 :
스토리지 엔진의 역할
•트랜잭션(Transaction Manager): 트랜잭션을 스케줄링하고 데이터베이스 상태의 논리적 일관성 보장.
•잠금 매니저(Lock Manager): 트랜잭션에서 접근하는 데이터베이스 객체에 대한 잠금을 제어. 동시 수행 작업이 물리적 데이터 무결성을 침해하지 않도록 함.
= 트랜잭션과 잠금 매니저는 동시성 제어. 논리적 물리적 데이터 무결성을 보장하고,
동시 수행 작업의 효율적 수행을 담당.
•엑세스 메서드(Access Method): 디스크에 저장된 데이터에 대한 접근 및 저장 방식을 정의. 힙 파일/B-트리/LSM 트리 등의 자료구조 사용.
•버퍼 매니저(Buffer Manager): 데이터 페이지를 메모리에 캐시.
•복구 매니저(Recovery Manager): 로그를 유지 관리하고 장애 발생 시 시스템을 복구
InnoDB와 MyISAM 비교
InnoDB
•MyISAM보다 데이터 저장비율이 낮고, 데이터 로드 속도가 느리다.
•레코드 기반의 락(Lock)을 제공한다. 즉, 테이블 레벨이 아닌 ROW 레벨의 락을 지원한다. 이로 인해 높은 동시성 처리가 가능한 특징이 있고 안정적이다. (Row - Level Lock)
→ Insert, Update, Delete에 대한 속도가 빠르다
•외부키를 지원한다
•자동 데드락 감지 : 감지 시 변경된 레코드가 가장 작은 트랜잭션을 롤백해버려서 데드락을 풀어준다.
•자동 장애 복구 : 완료하지 못한 트랜잭션이나 일부만 기록되어 손상된 데이터 페이지 등을 자동 복구한다.
•데이터 무결성 보장(트랜잭션, 외래키, 제약조건, 동시성 등) - ACID
•Primary Key를 기준으로 Clustering되어서 저장된다. 즉, PK를 기준으로 순서대로 디스크에 저장되는 구조로 PK에 의한 Range Scan이 빠르다.
→ 데이터를 PK순서에 맞게 저장한다는 뜻이므로 Order By 등 쿼리에 유리할 수 있다.
•인덱스와 더불어 데이터까지 버퍼풀에 저장하기 때문에 모든 데이터가 메모리에 있으면 디스크를 읽지 않아도 된다.
→ 데이터 접근 속도가 빠르다
→ 인덱스와 데이터 모두 메모리에 적재되므로 메모리 사용 효율에 좋지 않다.
→ 메모리 때문에 로그 수집에 대한 용도로 InnoDB를 사용하면 안된다.
MyISAM
•구조가 단순해, 속도가 빠르다.
•데이터 저장에 실제적인 제한이 없고 매우 효율적으로 저장한다.
→ 메모리 효율이 InnoDB보다 좋음
•테이블 작업시 특정 행을 수정하려고 하면 테이블 전체에 락이 걸려서 다른사람이 작업 할 수 없다. (Table-level Lock)
→ 갱신이 많은 용도로는 성능적으로 불리. 동시 서비스에 적합X
→ multi-thread 환경에서는 성능이 저하될 수 있다.
•트랜잭션에 대한 지원이 없기때문에 작업도중 문제가 생겨도 이미 DB안으로 데이터가 들어감. DB 프로세스가 비정상 종료하면 테이블이 파손될 가능성이 높다.
→ 데이터 무결성이 보장되지 않는다.
•Full-text 검색이 가능하다
•주로 select 작업이 많은 경우에 사용된다. 즉, 읽기(READ)작업에 효과적이다.
InnoDB와 MyISAM 간단 비교
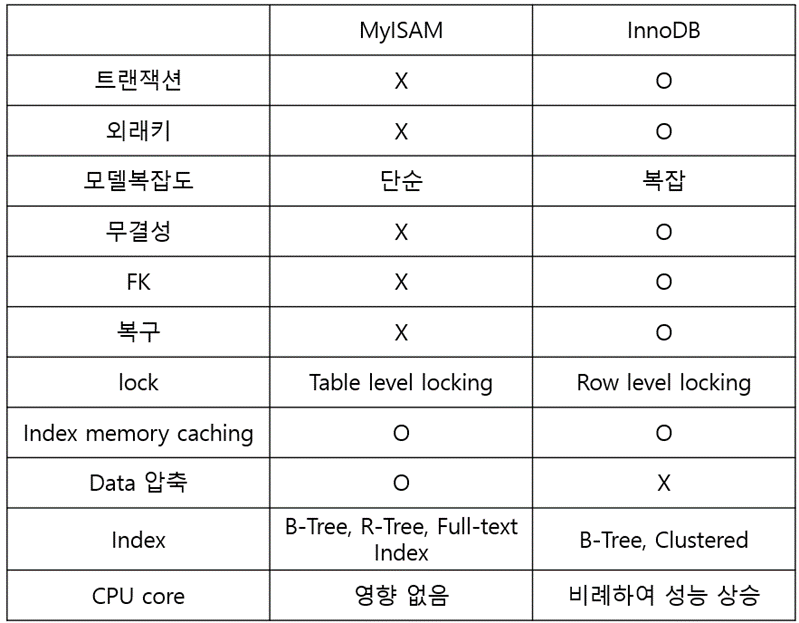
InnoDB: 복잡해서 속도가 비교적 느리지만 다양한 기능을 제공하고 데이터를 더 안전하게 저장 가능
MyISAM: 단순해서 속도가 비교적 빠르지만 지원하지 않는 기능들도 있어 성능면에서는 비교적 떨어진다.
'2-1 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스 14주차 정리 (0) | 2023.06.04 |
|---|---|
| 데이터베이스 13주차 정리 (2) | 2023.06.03 |
| 데이터베이스 12주차 정리 (0) | 2023.05.22 |
| 데이터베이스 11주차 정리 (0) | 2023.05.15 |
| 데이터베이스 10주차 정리 (0) | 2023.05.08 |



